
A non-blocking lexing toolkit for Scala based on the derivative of regular expressions. More resources What's a lexer?

A lexer is a string-eating state machine that uses regular expressions to define transitions from one state to another. Lexers appear most frequently as the very first phase of a compiler, where they're used to "tokenize" the input. They ought to appear more frequently as protocol-parsers, but the blocking I described makes them unsuitable. Lex is a lexer-generator tool that outputs C code. <STATE> regex { action } In English, each rule means "if in state STATE and regex matches the longest prefix of the remaining input, match this prefix and perform action.
" I have another article on lexers (in JavaScript) if you want to know more. A Scala DSEL for regular expressions To embed a lexing toolkit in Scala, we'll need a way to describe regular expressions. The heart of the DSEL is the class RegularLanguage, whose interface describes all of the regular operations: Live Streams: A non-blocking interface So, it's almost exactly a linked list. Example: A lexer for Scheme. You're Doing It Wrong. Related Content Browse this Topic: Queue on Reddit Poul-Henning Kamp Would you believe me if I claimed that an algorithm that has been on the books as "optimal" for 46 years, which has been analyzed in excruciating detail by geniuses like Knuth and taught in all computer science courses in the world, can be optimized to run 10 times faster?
A couple of years ago, I fell into some interesting company and became the author of an open source HTTP accelerator called Varnish, basically an HTTP cache to put in front of slow Web servers. Having spent 15 years as a lead developer of the FreeBSD kernel, I arrived in user land with a detailed knowledge of what happens under the system calls. Because, not to mince words, the majority of you are doing that wrong. Regular Expression Matching Can Be Simple And Fast. Russ Coxrsc@swtch.com January 2007 Introduction This is a tale of two approaches to regular expression matching.
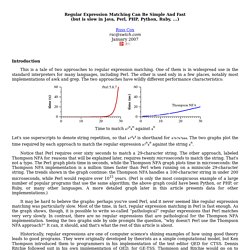
One of them is in widespread use in the standard interpreters for many languages, including Perl. The other is used only in a few places, notably most implementations of awk and grep. The two approaches have wildly different performance characteristics: Let's use superscripts to denote string repetition, so that a? Notice that Perl requires over sixty seconds to match a 29-character string.
It may be hard to believe the graphs: perhaps you've used Perl, and it never seemed like regular expression matching was particularly slow. Historically, regular expressions are one of computer science's shining examples of how using good theory leads to good programs. Today, regular expressions have also become a shining example of how ignoring good theory leads to bad programs. Regular Expressions Regular expressions are a notation for describing sets of character strings.
Finite Automata. Oracle Regular Expressions.