
1210ijcsit13. SystemML - Publications. Feedback Group Name SystemML Compressed Linear Algebra for Large-Scale Machine Learning Ahmed Elgohary, Matthias Boehm, Peter J.
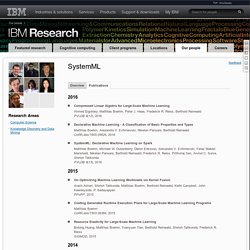
Want an open-source deep learning framework? Take your pick. Earlier this week, Google made a splash when it released its TensorFlow artificial intelligence software on GitHub under an open-source license.
Google has a sizable stable of AI talent, and AI is working behind the scenes in popular products, including Gmail and Google search, so AI tools from Google are a big deal. Today on GitHub, TensorFlow, primarily written in C++, is the top trending project of the day, the week, and the month, having accrued more than 10,000 stars in about one week. But there are several other open-source tools to choose from on GitHub if you want to improve your app with deep learning, a type of AI that involves training artificial neural networks on a bunch of data and then getting them to make inferences about new data.
Here’s a rundown of some other notable deep learning libraries available today. Deep Learning Frameworks. Deep learning frameworks offer building blocks for designing, training and validating deep neural networks, through a high level programming interface.
Widely used deep learning frameworks such as MXNet, PyTorch, TensorFlow and others rely on GPU-accelerated libraries such as cuDNN, NCCL and DALI to deliver high-performance multi-GPU accelerated training. Developers, researchers and data scientists can get easy access to NVIDIA optimized deep learning framework containers with deep learning examples, that are performance tuned and tested for NVIDIA GPUs. This eliminates the need to manage packages and dependencies or build deep learning frameworks from source.
Popular Deep Learning Tools – a review. Deep Learning is the hottest trend now in AI and Machine Learning.
We review the popular software for Deep Learning, including Caffe, Cuda-convnet, Deeplearning4j, Pylearn2, Theano, and Torch. Deep Learning is now of the hottest trends in Artificial Intelligence and Machine Learning, with daily reports of amazing new achievements, like doing better than humans on IQ test. In 2015 KDnuggets Software Poll, a new category for Deep Learning Tools was added, with most popular tools in that poll listed below. Analytics, Data Mining, and Data Science. The Next Big Inflection in Big Data: Automated Insights. By Evangelos Simoudis, @esimoudis, Corporate Innovation Ventures.
In previous posts, I wrote about the need for insight generation and provided an example of an insightful application. I maintain that insightful applications are the key to businesses effectively exploiting big data in order to improve decision-making and address important problems. To better understand and appreciate the need for developing such applications, it is important to consider what is happening more broadly in big data and evaluate how our experiences with business intelligence systems should be driving our thinking about insightful applications.
Because I consider insightful applications the next inflection in big data (see recent examples of such applications built using IBM’s Watson platform), I would like to further explore this topic in a series of blog posts. Interview: Ingo Mierswa, RapidMiner CEO on “Predaction” and Key Turning Points. By Ajay Ohri, DecisionStats, June 2014.
Here is my interview with Ingo Mierswa, co-founder and CEO of RapidMiner. Ingo Mierswa is an industry-veteran data scientist since starting to develop RapidMiner at the AI Division of the University of Dortmund, Germany. Mierswa has authored numerous award-winning publications about predictive analytics and big data. Mierswa, the entrepreneur, is the founder of RapidMiner.
Security and Intelligence Solutions. Analyst's Notebook 6, from i2 Inc., conducts sophisticated link analysis, timeline analysis and data visualization for complex investigations.
Centrifuge, offers analysts and investigators an integrated suite of capabilities that can help them rapidly understand and glean insight from new data sources. InferX, remote data mining solutions for law enforcement, intrusion detection, and related applications. NORA™ (Non-Obvious Relationship Awareness™), identifies potentially alarming non-obvious relationships among and between individuals and companies QinetiQ Knowledge Discovery Appliance, provides timely intelligence by real-time processing of high volumes of data using an iterative learning engine that evaluates context based on attributes and associations to determine relevancy and value of data.
CDMC2013: Cybersecurity Data Mining Competition. CDMC2013: The 4th International Cybersecurity Data Mining Competition cdmc2013.csmining.org Objectives The purpose of the International Cybersecurity Data Mining Competition is to increase awareness of Cybersecurity and the potential of industrial applications, and give young researchers exposure to the main issues related to the topic and to ongoing work in this area.
The focus of this competition is on string sequences analysis towards application of knowledge discovery techniques for protecting personal computer information by means of detection, preventive measures, and responding to various attacks. Tasks and Data. Anomaly Detection in Predictive Maintenance with Time Series Analysis. By Rosaria Silipo The Newest Challenge Most of the data science use cases are relatively well established by now: a goal is defined, a target class is selected, a model is trained to recognize/predict the target, and the same model is applied to new never-seen-before productive data.

The newest challengelies in predicting the “unknown”, i.e. an anomaly. An anomaly is an event that is not part of the system’s past; an event that cannot be found in the system’s historical data. In the case of network data, an anomaly can be an intrusion, in medicine a sudden pathological status, in sales or credit card businesses a fraudulent payment, and, finally, in machinery a mechanical piece breakdown. Fraud Detection Solutions.
Alaric Systems "Fractals" card fraud detection and prevention systems using proprietary inference techniques based on Bayesian methods.
Analyst's Notebook 6, from IBM, conducts sophisticated link analysis, timeline analysis and data visualization for complex investigations. Apollo Wipro fraud detection platform, leveraging Big Data and machine learning, with pre-built models for procurement, payments, workforce policy compliance, resource management, and regulatory & contractual violations. Aptelisense Compliance Automation Server, advanced real-time fraud prevention and data compliance that requires zero change to applications or systems. ArcSight AntiFraud Accelerator Solution.
Austin Logistics FraudAlert, solutions for collections, marketing, and risk management for consumer credit and Internet transactions. Data Mining and other covert collection of information.