
S3-Examples. Configuring Amazon S3 Event Notifications. The Amazon S3 notification feature enables you to receive notifications when certain events happen in your bucket.
To enable notifications, you must first add a notification configuration identifying the events you want Amazon S3 to publish, and the destinations where you want Amazon S3 to send the event notifications. You store this configuration in the notification subresource (see Bucket Configuration Options) associated with a bucket. Hive : How To Create A Table From CSV Files in S3. Say your CSV files are on Amazon S3 in the following directory: Files can be plain text files or text files gzipped: $ aws s3 ls 2015-07-06 00:37:06 0 2015-07-06 00:37:17 74796978 file_a.txt.gz 2015-07-06 00:37:20 84324787 file_b.txt.gz 2015-07-06 00:37:22 85376585 file_b.txt.gz To create a Hive table on top of those files, you have to specify the structure of the files by giving columns names and types.
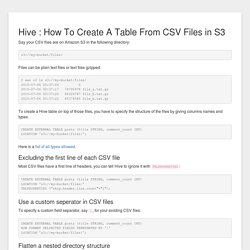
CREATE EXTERNAL TABLE posts (title STRING, comment_count INT) LOCATION ' Here is a list of all types allowed. Excluding the first line of each CSV file Most CSV files have a first line of headers, you can tell Hive to ignore it with TBLPROPERTIES: CREATE EXTERNAL TABLE posts (title STRING, comment_count INT) LOCATION ' TBLPROPERTIES ("skip.header.line.count"="1"); Use a custom seperator in CSV files To specify a custom field separator, say |, for your existing CSV files: CREATE EXTERNAL TABLE posts (title STRING, comment_count INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LOCATION '
How to create username and password for AWS Management Console. Working with AWS Login Profiles. Recently, AWS IAM Team announced support for Login Profiles - an easy and convenient way to create username/password pairs which can be used to sign-in and use AWS Management Console and AWS Developer Forums.
Basic HTTP Auth for S3 Buckets. Amazon S3 is a simple and very useful storage of binary objects (aka "files").

To use it, you create a "bucket" there with a unique name and upload your objects. Afterwards, AWS guarantees your object will be available for download through their RESTful API. A few years ago, AWS introduced a S3 feature called static website hosting. With static website hosting, you simply turn on the feature and all objects in your bucket become available through public HTTP. This is an awesome feature for hosting static content, such as images, JavaScript files, video and audio content.
Redgate Software - Tools for SQL Server, .NET, & Oracle. Mikeaddison93/es-amazon-s3-river. Local Gateway. The local gateway allows for recovery of the full cluster state and indices from the local storage of each node, and does not require a common node level shared storage.
Note, different from shared gateway types, the persistency to the local gateway is not done in an async manner. Once an operation is performed, the data is there for the local gateway to recover it in case of full cluster failure. It is important to configure the gateway.recover_after_nodes setting to include most of the expected nodes to be started after a full cluster restart. This will insure that the latest cluster state is recovered. For example: gateway: recover_after_nodes: 1 recover_after_time: 5m expected_nodes: 2 Dangling indicesedit When a node joins the cluster, any shards/indices stored in its local data/ directory which do not already exist in the cluster will be imported into the cluster by default.
The import of dangling indices can be controlled with the gateway.local.auto_import_dangled which accepts: Connecting to a DB Instance Running the MySQL Database Engine - Amazon Relational Database Service. Once Amazon RDS provisions your DB instance, you can use any standard MySQL client application or utility to connect to the instance.
In the connection string, you specify the DNS address from the DB instance endpoint as the host parameter, and specify the port number from the DB instance endpoint as the port parameter. You can use the AWS Management Console, the rds-describe-db-instances CLI command, or the DescribeDBInstances API action to list the details of an Amazon RDS DB instance, including its endpoint. If an endpoint value is myinstance.123456789012.us-east-1.rds.amazonaws.com:3306, then you would specify the following values in a MySQL connection string: Connecting to an AWS RDS Database Using MySQL Monitor, or MySQL Workbench. Hi everyone, For one of my projects, I’ve been playing around with AWS for some time.

Amazon Web Services (AWS) is pretty much a huge collection of amazing computing, networking, databasing, etc. resources which you can use to create just about anything! Among the many obstacles I’ve encountered along the way – wouldn’t be fun without them – my latest one was connecting to the RDS instance so I can actually see what’s happening. I mean, I can SSH into EC2, and probably access RDS from there. But I want the convenience of popping up a local terminal and running one command to get into my RDS instance. Here’s what you do: In your AWS Management Console, go to RDSClick on the RDS DB instance you are trying to accessIn the drop-down area, you should see additional details. That’s it, everything should work as planned now. Connect to Your Cluster by Using SQL Workbench/J - Amazon Redshift.
Amazon Redshift does not provide or install any SQL client tools or libraries, so you must install any that you want to use with your clusters.
If you already have a business intelligence application or any other application that can connect to your clusters using a standard PostgreSQL JDBC or ODBC driver, then you can skip this section. If you don't already have an application that can connect to your cluster, this section presents one option for doing so using SQL Workbench/J, a free, DBMS-independent, cross-platform SQL query tool. The Amazon Redshift Getting Started uses SQL Workbench/J. In this section, we explain in detail how to connect to your cluster by using SQL Workbench/J. S3 Browser - How to copy/move files and folders from one Amazon S3 Bucket to another. Using Cyberduck with S3. 01 September 2014 In my previous post, I mentioned that I am moving away from WordPress for my personal blog in favor of a static publishing tool (currently Pelican).
The downside of static tools is that they require a change in workflow. You can't just write a post and hit publish. You have to write a post, then run a script, then upload these newly-generated HTML pages. It's possible to automate the uploading part with a script.