
Spark-Scala code Analyzers. Auto Scaling. Whether you are running one Amazon EC2 instance or thousands, you can use Auto Scaling to detect impaired Amazon EC2 instances and unhealthy applications, and replace the instances without your intervention.
This ensures that your application is getting the compute capacity that you expect. Auto Scaling enables you to follow the demand curve for your applications closely, reducing the need to manually provision Amazon EC2 capacity in advance. For example, you can set a condition to add new Amazon EC2 instances in increments to the Auto Scaling group when the average utilization of your Amazon EC2 fleet is high; and similarly, you can set a condition to remove instances in the same increments when CPU utilization is low.
Getting Started with Auto Scaling - Auto Scaling. Whenever you plan to use Auto Scaling, you must use certain building blocks to get started.
This tutorial walks you through the process for setting up the basic infrastructure for Auto Scaling. The following step-by-step instructions help you create a template that defines your EC2 instances, create an Auto Scaling group to maintain the healthy number of instances at all times, and optionally delete this basic Auto Scaling infrastructure. This tutorial assumes that you are familiar with launching EC2 instances and have already created a key pair and a security group.
Step 1: Create a Launch Configuration A launch configuration specifies the type of EC2 instance that Auto Scaling creates for you. To create a launch configuration Open the Amazon EC2 console at the navigation bar, select a region. Configure Spark (EMR 4.x Releases) - Amazon Elastic MapReduce. Configuration - Spark 1.6.1 Documentation. Spark provides three locations to configure the system: Spark properties control most application parameters and can be set by using a SparkConf object, or through Java system properties.
Environment variables can be used to set per-machine settings, such as the IP address, through the conf/spark-env.sh script on each node. Job Scheduling - Spark 1.6.1 Documentation. Spark has several facilities for scheduling resources between computations.

First, recall that, as described in the cluster mode overview, each Spark application (instance of SparkContext) runs an independent set of executor processes. The cluster managers that Spark runs on provide facilities for scheduling across applications. Second, within each Spark application, multiple “jobs” (Spark actions) may be running concurrently if they were submitted by different threads. This is common if your application is serving requests over the network.
Catalyst: A Functional Query Optimizer for Spark and Shark. Introduction to Spark 2.0 - Part 6 : Custom Optimizers in Spark SQL. Sigmod spark sql. OpenJDK: jol. JOL (Java Object Layout) is the tiny toolbox to analyze object layout schemes in JVMs.
These tools are using Unsafe, JVMTI, and Serviceability Agent (SA) heavily to decoder the actual object layout, footprint, and references. This makes JOL much more accurate than other tools relying on heap dumps, specification assumptions, etc. Building JOL from source You may skip this step and use the published binaries instead, see the usage below. It is generally preferred to use the latest source version, that hopefully has the most issues fixed. Project Tungsten: Bringing Spark Closer to Bare Metal. In a previous blog post, we looked back and surveyed performance improvements made to Apache Spark in the past year.
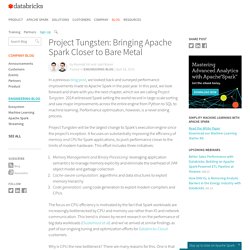
In this post, we look forward and share with you the next chapter, which we are calling Project Tungsten. 2014 witnessed Spark setting the world record in large-scale sorting and saw major improvements across the entire engine from Python to SQL to machine learning. Performance optimization, however, is a never ending process. Project Tungsten will be the largest change to Spark’s execution engine since the project’s inception. It focuses on substantially improving the efficiency of memory and CPU for Spark applications, to push performance closer to the limits of modern hardware.
This effort includes three initiatives: The focus on CPU efficiency is motivated by the fact that Spark workloads are increasingly bottlenecked by CPU and memory use rather than IO and network communication. Why is CPU the new bottleneck? Deep Dive into Spark SQL’s Catalyst Optimizer. Spark SQL is one of the newest and most technically involved components of Spark.

It powers both SQL queries and the new DataFrame API. At the core of Spark SQL is the Catalyst optimizer, which leverages advanced programming language features (e.g. Scala’s pattern matching and quasiquotes) in a novel way to build an extensible query optimizer. We recently published a paper on Spark SQL that will appear in SIGMOD 2015 (co-authored with Davies Liu, Joseph K. Bradley, Xiangrui Meng, Tomer Kaftan, Michael J. To implement Spark SQL, we designed a new extensible optimizer, Catalyst, based on functional programming constructs in Scala.
At its core, Catalyst contains a general library for representing trees and applying rules to manipulate them. Tips and Tricks for Running Spark on Hadoop, Part 1: Execution Modes - Altiscale. As more of our customers begin running Spark on Hadoop, we’ve identified—and helped them to overcome—some challenges they commonly face.
To help other organizations tackle these hurdles, we’re launching this series of blog posts that will share tips and tricks for quickly getting up and running on Spark and reducing overall time to value. Our focus is Spark running on Hadoop, which is how we run Spark as a Service. But which versions are best? As both Spark and Hadoop continue to rapidly evolve, it’s important to run relatively recent versions of both in order to gain the maximum benefit.
Quasiquotes - Introduction. Denys Shabalin EXPERIMENTAL Quasiquotes are a neat notation that lets you manipulate Scala syntax trees with ease: scala> val tree = q"i am { a quasiquote }"tree: universe.Tree = i.am(a.quasiquote) Every time you wrap a snippet of code into q"...
" quotation it would become a tree that represents given snippet. As you might have already noticed quotation syntax is in just another usage of extensible string interpolation introduced in 2.10. Although they look like strings they operate on syntactic trees under the hood. The same syntax can be used to match trees as patterns: scala> println(tree match { case q"i am { a quasiquote }" => "it worked! " Understanding the Catalyst optimizer - Spark Cookbook [Book]