
Iesurvey2006. Information Extraction Task - GM-RKB. An information extraction (IE) task is a data processing task that requires the population of a data structure with the information contained in non-fully-structured data.
(Wikipedia, 2009) ⇒ Information extraction (IE) is the task of automatically extracting structured information from unstructured and/or semi-structured machine-readable documents. In most of the cases this activity concerns processing human language texts by means of natural language processing (NLP). Recent activities in multimedia document processing like automatic annotation and content extraction out of images/audio/video could be seen as information extraction. Due to the difficulty of the problem, current approaches to IE focus on narrowly restricted domains. An example is the extraction from news wire reports of corporate mergers, such as denoted by the formal relation: , from an online news sentence such as: "Yesterday, New-York based Foo Inc. announced their acquisition of Bar Corp. " Competition. LingPipe's Competition On this page, we break our competition down into academic toolkits and industrial toolkits.

We only consider software that is available for linguistic processing, not companies that rely on linguistic processing in an application but do not sell that technology. How does LingPipe compare to the below offerings? A few key points to keep in mind as you browse the offerings: We are a Geek2Geek business. Academic and Open Source Competition The following is a list of ongoing large-scale, multi-function natural language toolkits that are built and distributed by academics.
ABNER is a statistical named entity recognizer "using linear-chain conditional random fields (CRFs) with a variety of orthographic and contextual features. Information Technology Laboratory Homepage. Linguistic Data Consortium. The objective of the Automatic Content Extraction (ACE) Program was to develop extraction technology to support automatic processing of source language data (in the form of natural text and as text derived from ASR and OCR).
Automatic processing, defined at that time, included classification, filtering, and selection based on the language content of the source data, i.e., based on the meaning conveyed by the data. Thus the ACE program required the development of technologies that automatically detect and characterize this meaning. The ACE research objectives were viewed as the detection and characterization of Entities, Relations, and Events.
LDC developed annotation guidelines, corpora and other linguistic resources to support the ACE Program. Some of these resources were developed in cooperation with the TIDES Program in support of TIDES Extraction evaluations. Entity Detection and Tracking (EDT) was the core annotation task, providing the foundation for all remaining tasks. Information Extraction Engine. Next: Experimental ResultsUp: Knowledge-based Information Agents Previous: Three Knowledge Bases The information extraction engine utilizes the three categories of knowledge, extracts information from Web pages and saves the information as structured data.

Figure shows how it works. Entity Extraction Engine - Elder Research Inc. Natural Language Processing Software. Terminology extraction. This page describes how to extract terminology from your own corpora.
Terminology extraction is also available in preloaded corpora via word list feature. For extraction terminology between languages, see bilingual terminology extraction. Keywords and terms Sketch Engine allows you to create a list of terminology used in your corpus. Terminology items are divided into keywords and terms. How to extract terminology Open your corpus, click Manage corpus and select the Keywords & terms button in the submenu Search corpus. The left table displays keywords and the right column displays terms.
Extraction option You may tune the result of extracting terminology in the Change extraction options form at the bottom of the same page (below the result). Search terminology on Wikipedia Every word has a link to the five most relevant pages in Wikipedia. Apache Stanbol - The Named Entity Extraction Engine. This engine detects named entities from unstructured text.
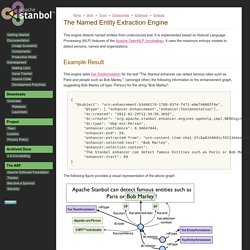
It is implemented based on Natural Language Processing (NLP) features of the Apache OpenNLP (incubating). It uses the maximum entropy models to detect persons, names and organizations. This engine adds fise:TextAnnotation for the text "The Stanbol enhancer can detect famous cities such as Paris and people such as Bob Marley. ", (amongst other) the following information to the enhancement graph, suggesting Bob Marley (of type: Person) for the string "Bob Marley":