
Getting Started with Elasticsearch and Kibana on Amazon EMR - AWS Big Data Blog. How to install and configure Kibana in AWS. Kibana is basically the visualisation tool of Elasticsearch.
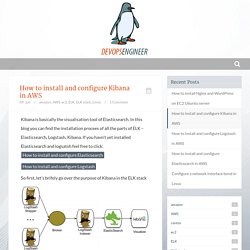
In this blog you can find the installation procees of all the parts of ELK – Elasticsearch, Logstash, Kibana. If you havn’t yet installed Elasticsearch and logsatsh feel free to click: How to install and configure Elasticsearch How to install and configure Logstash So first, let’s brifely go over the purpose of Kibana in the ELK stack This picture is very helpfull to understanding what is the purposes of Kibana. 1. 2. 3.Visualise data – in a browser-based analytics and search dashboard Step 1: Installation The first step is getting the installation from the official website: [root@kibana ~] wget Next, extract the file: [root@kibana ~] tar xzf kibana-4.0.1-linux-x64.tar.gz Step 2: Configuration Next let’s go into the Kibana directory: [root@kibana ~] cd kibana-4.0.1-linux-x64 Open the yml configuration file: [root@kibana ~] vi config/kibana.yml Now the only thing we need to configure in here is the URL of Elasticsearch.
Getting Started with Elasticsearch and Kibana on Amazon EMR. Citrix Access Gateway. Elasticsearch in Apache Spark with Python—Machine Learning Series, Part 2. Introductory note: Sloan Ahrens is a co-founder of Qbox who is now a freelance data consultant.

This is the second in a series of guest posts, in which he demonstrates how to set up a large scale machine learning infrastructure using Apache Spark and Elasticsearch. -Mark Brandon In this post we're going to continue setting up some basic tools for doing data science. We began the setup in our first article in this series, Building an Elasticsearch Index with Python, Machine Learning Series, Part 1. The goal of this instruction throughout the series is to run machine learning classification algorithms against large data sets, using Apache Spark and Elasticsearch clusters in the cloud. Here we will complete our setup by installing Spark on the VM that we established with the steps given in the first article.
For this second segment, we'll remain local on our Ubuntu 14 VM. Step 1: Gear Check Also, you might like to ensure that your VM has access to several processors. . # download spark wget. Connecting to Your Linux Instance Using SSH - Amazon Elastic Compute Cloud. After you launch your instance, you can connect to it and use it the way that you'd use a computer sitting in front of you.
Note After you launch an instance, it can take a few minutes for the instance to be ready so that you can connect to it. Check that your instance has passed its status checks - you can view this information in the Status Checks column on the Instances page. The following instructions explain how to connect to your instance using an SSH client. If you receive an error while attempting to connect to your instance, see Troubleshooting Connecting to Your Instance. Before you connect to your Linux instance, complete the following prerequisites: Install an SSH clientYour Linux computer most likely includes an SSH client by default. AWS Toolkit for Eclipse. Articles & Tutorials. Showing 1-15 of 15 results.
Sort by: This tutorial is now deprecated. To learn more about Spark on Amazon EMR, click here. This tutorial walks you through installing and operating Spark, a fast and general engine for large-scale data processing, on an Amazon EMR cluster. You will also create and query a dataset in Amazon S3 using Spark SQL, and learn how to monitor Spark on an Amazon EMR cluster with Amazon CloudWatch. Last Modified: Jun 16, 2015 23:25 PM GMT An internet advertising company operates a data warehouse using Hive and Amazon Elastic MapReduce. Last Modified: Apr 29, 2015 17:47 PM GMT Analyze your Amazon CloudFront Logs using Amazon Elastic MapReduce. Last Modified: Dec 8, 2014 21:07 PM GMT This article shows how to use EMR to efficiently export DynamoDB tables to S3, import S3 data into DynamoDB, and perform sophisticated queries across tables stored in both DynamoDB and other storage services such as S3. Last Modified: Sep 26, 2013 0:23 AM GMT Last Modified: Mar 6, 2013 0:05 AM GMT.