
Home — Project Kenai. Home — Project Kenai. Logstash Reference [2.4] Logstash has a rich collection of input, filter, codec and output plugins.
![Logstash Reference [2.4]](http://cdn.pearltrees.com/s/pic/th/working-logstash-reference-117124249)
Plugins are available as self-contained packages called gems and hosted on RubyGems.org. The plugin manager accessed via bin/logstash-plugin script is used to manage the lifecycle of plugins in your Logstash deployment. You can install, uninstall and upgrade plugins using the Command Line Interface (CLI) invocations described below. Listing pluginsedit Logstash release packages bundle common plugins so you can use them out of the box. Adding plugins to your deploymentedit The most common situation when dealing with plugin installation is when you have access to internet. Elasticsearch-py. What Is Amazon Elasticsearch Service? - Amazon Elasticsearch Service. Amazon Elasticsearch Service (Amazon ES) is a managed service that makes it easy to deploy, operate, and scale Elasticsearch clusters in the AWS cloud.
Elasticsearch is a popular open-source search and analytics engine for use cases such as log analytics, real-time application monitoring, and clickstream analytics. How to install and configure Kibana in AWS. Kibana is basically the visualisation tool of Elasticsearch.
In this blog you can find the installation procees of all the parts of ELK – Elasticsearch, Logstash, Kibana. 5-minute Logstash: Parsing and Sending a Log File. December 19, 2013 by Radu Gheorghe We like Logstash a lot at Sematext, because it’s a good (if not the) swiss-army knife for logs.
Plus, it’s one of the easiest logging tools to get started with, which is exactly what this post is about. In less than 5 minutes, you’ll learn how to send logs from a file, parse them to extract metrics from those logs and send them to Logsene, our logging SaaS (basically, ELK Stack in the Cloud, though you can get an On Premises version, too, if you really want) NOTE: Because Logsene exposes the Elasticsearch API, the same steps will work if you have a local Elasticsearch cluster.
NOTE: If this sort of stuff excites you, we are hiring world-wide for positions from devops and core product engineering to marketing and sales. Overview As an example, we’ll take an Apache log, written in its combined logging format. The Input The first part of your configuration file would be about your inputs. The Filter The Output The complete output configuration would be: Getting Started with Kibana. Mikeaddison93/es-amazon-s3-river.
Local Gateway. The local gateway allows for recovery of the full cluster state and indices from the local storage of each node, and does not require a common node level shared storage.
Note, different from shared gateway types, the persistency to the local gateway is not done in an async manner. Once an operation is performed, the data is there for the local gateway to recover it in case of full cluster failure. It is important to configure the gateway.recover_after_nodes setting to include most of the expected nodes to be started after a full cluster restart. This will insure that the latest cluster state is recovered. Getting Started with Elasticsearch and Kibana on Amazon EMR. AWS GovCloud and ElasticBox: A complementary union. AWS GovCloud is one of the several popular clouds where ElasticBox orchestrates and automates the lifecycle of applications.

AWS GovCloud (US) is an isolated AWS Region for US government agencies and businesses to move sensitive workloads primarily because of regulatory and compliance requirements. If you’re curious about the use-cases for AWS GovCloud and the value ElasticBox adds, you’re at the right spot. Amazon GovCloud targets two kinds of usage: Businesses that don’t have ITAR data but want to embrace the extra security layer in this region.Government agencies or businesses with confidential data that must enforce regulatory compliance and security measures. I’ll talk about some of the key scenarios where it makes sense to use AWS GovCloud: High availability is important for mission critical apps in Oracle, SAP, and Windows. For all these scenarios, AWS GovCloud provides agencies and businesses the elasticity of AWS with the security of an ITAR and FedRAMP compliant infrastructure. Input plugins.
Working with plugins. Setting Up an Advanced Logstash Pipelineedit A Logstash pipeline in most use cases has one or more input, filter, and output plugins.
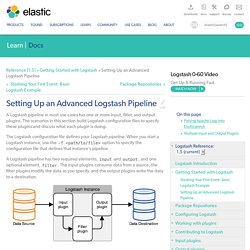
The scenarios in this section build Logstash configuration files to specify these plugins and discuss what each plugin is doing. The Logstash configuration file defines your Logstash pipeline. When you start a Logstash instance, use the -f <path/to/file> option to specify the configuration file that defines that instance’s pipeline. A Logstash pipeline has two required elements, input and output, and one optional element, filter. The following text represents the skeleton of a configuration pipeline: # The # character at the beginning of a line indicates a comment. This skeleton is non-functional, because the input and output sections don’t have any valid options defined.
Paste the skeleton into a file named first-pipeline.conf in your home Logstash directory. Using Elasticsearch on Amazon EC2. Elasticsearch • amazon-ec2 Elasticsearch is a distributed search server offering powerful search functionality over schema-free documents in (near) real time.

All of this functionality is exposed via a RESTful JSON API. It's built on top of Apache Lucene and like all great projects it's open source. Update: I've updated this post to be compatible with recent versions of Elasticsearch. I need to index about 80 million documents, and be able to easily perform complex queries over the dataset. Due to its distributed nature, Elasticsearch is ideal for this task, and EC2 provides a convenient platform to scale as required. I'd reccomend downloading a copy locally first and familiarising yourself with the basics, but if you want to jump straight in, be my guest. I'll assume you already have an Amazon AWS account, and can navigate yourself around the AWS console.
Using Elasticsearch on Amazon EC2.