
MapReduce. Overview[edit] MapReduce is a framework for processing parallelizable problems across huge datasets using a large number of computers (nodes), collectively referred to as a cluster (if all nodes are on the same local network and use similar hardware) or a grid (if the nodes are shared across geographically and administratively distributed systems, and use more heterogenous hardware).
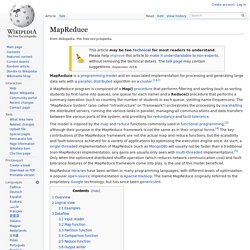
Processing can occur on data stored either in a filesystem (unstructured) or in a database (structured). MapReduce can take advantage of locality of data, processing it on or near the storage assets in order to reduce the distance over which it must be transmitted. "Map" step: Each worker node applies the "map()" function to the local data, and writes the output to a temporary storage. The SMAQ stack for big data. “Big data” is data that becomes large enough that it cannot be processed using conventional methods.

Creators of web search engines were among the first to confront this problem. Today, social networks, mobile phones, sensors and science contribute to petabytes of data created daily. Oracle has a cloud computing secret. There’s a reason Larry Ellison called cloud computing “nonsense” in 2009 and why he still won’t permit Amazon-style metered pricing for Oracle’s mainstream database and middleware.

A traditional 11g database license that today costs $2.8 million up front would cost less than $9 per hour using Oracle’s mySQL on Amazon. (Keep reading to see why this apples-to-oranges comparison is valid.) We’ve seen a similar scenario play out before — back when IBM mainframes ran mission-critical applications on legacy databases. IBM actually pioneered relational databases, but it was conflicted about selling the lower-priced, lower-margin servers needed to run them. These servers had the price-to-performance ratio customers needed for the performance-hungry RDBs.