
NP (complexity) In computational complexity theory, NP is one of the most fundamental complexity classes.
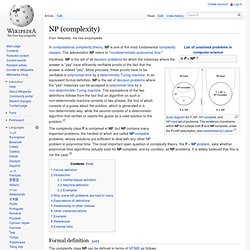
The abbreviation NP refers to "nondeterministic polynomial time. " Intuitively, NP is the set of all decision problems for which the instances where the answer is "yes" have efficiently verifiable proofs of the fact that the answer is indeed "yes". More precisely, these proofs have to be verifiable in polynomial time by a deterministic Turing machine. In an equivalent formal definition, NP is the set of decision problems where the "yes"-instances can be accepted in polynomial time by a non-deterministic Turing machine.
The equivalence of the two definitions follows from the fact that an algorithm on such a non-deterministic machine consists of two phases, the first of which consists of a guess about the solution, which is generated in a non-deterministic way, while the second consists of a deterministic algorithm that verifies or rejects the guess as a valid solution to the problem.[2] Thomas H.
Complexity class. In computational complexity theory, a complexity class is a set of problems of related resource-based complexity.
A typical complexity class has a definition of the form: the set of problems that can be solved by an abstract machine M using O(f(n)) of resource R, where n is the size of the input. The simpler complexity classes are defined by the following factors: Many complexity classes can be characterized in terms of the mathematical logic needed to express them; see descriptive complexity. The Blum axioms can be used to define complexity classes without referring to a concrete computational model. Important complexity classes[edit] Many important complexity classes can be defined by bounding the time or space used by the algorithm.
It turns out that PSPACE = NPSPACE and EXPSPACE = NEXPSPACE by Savitch's theorem. Reduction[edit] Many complexity classes are defined using the concept of a reduction. The most commonly used reduction is a polynomial-time reduction. Hierarchy theorems[edit] Computational complexity theory. Computational complexity theory is a branch of the theory of computation in theoretical computer science and mathematics that focuses on classifying computational problems according to their inherent difficulty, and relating those classes to each other.
A computational problem is understood to be a task that is in principle amenable to being solved by a computer, which is equivalent to stating that the problem may be solved by mechanical application of mathematical steps, such as an algorithm. A problem is regarded as inherently difficult if its solution requires significant resources, whatever the algorithm used. The theory formalizes this intuition, by introducing mathematical models of computation to study these problems and quantifying the amount of resources needed to solve them, such as time and storage. Closely related fields in theoretical computer science are analysis of algorithms and computability theory. Computational problems[edit] Problem instances[edit] Turing machine[edit]
Abstract machine. An abstract machine, also called an abstract computer, is a theoretical model of a computer hardware or software system used in automata theory.
Abstraction of computing processes is used in both the computer science and computer engineering disciplines and usually assumes discrete time paradigm. Information[edit] In the theory of computation, abstract machines are often used in thought experiments regarding computability or to analyze the complexity of algorithms (see computational complexity theory). A typical abstract machine consists of a definition in terms of input, output, and the set of allowable operations used to turn the former into the latter. The best-known example is the Turing machine. More complex definitions create abstract machines with full instruction sets, registers and models of memory. Articles concerning Turing-equivalent sequential abstract machine models[edit] Family: Turing-equivalent (TE) abstract machine: Subfamilies: Subfamily (1) Sequential TE abstract machine.