
RMTrees. LMAX - How to Do 100K TPS at Less than 1ms Latency. A simple disruptor based actor. What's so special about a ring buffer? Recently we open sourced the LMAX Disruptor, the key to what makes our exchange so fast.
Why did we open source it? Well, we've realised that conventional wisdom around high performance programming is... a bit wrong. We've come up with a better, faster way to share data between threads, and it would be selfish not to share it with the world. Plus it makes us look dead clever. Disruptor - Concurrent Programming Framework. Haakan-Thesis. Java 2 Platform SE 5.0. Java theory and practice: Going atomic. Fifteen years ago, multiprocessor systems were highly specialized systems costing hundreds of thousands of dollars (and most of them had two to four processors).
Today, multiprocessor systems are cheap and plentiful, nearly every major microprocessor has built-in support for multiprocessing, and many support dozens or hundreds of processors. To exploit the power of multiprocessor systems, applications are generally structured using multiple threads. But as anyone who's written a concurrent application can tell you, simply dividing up the work across multiple threads isn't enough to achieve good hardware utilization -- you must ensure that your threads spend most of their time actually doing work, rather than waiting for more work to do, or waiting for locks on shared data structures.
The problem: coordination between threads. Flash Crisis. Robert X.

Cringely absolutely nails it in his recent column about some of the consequences of rapidly reducing IO times on programming languages1. His major point was that slow but expressive2 high-level scripting languages such as Ruby and Python have been getting away with their lack of performance due to slow disks. Is 2K ACID TPS fast for a disk based (scala) database? - scala-user. Solaris ZFS Performance Tuning: Synchronous Writes and the ZIL. When talking to customers, partners and colleagues about Oracle Solaris ZFS performance, one topic almost always seems to pop up: Synchronous writes and the ZIL.

19.2. Enabling/Disabling Write Barriers. To mitigate the risk of data corruption during power loss, some storage devices use battery-backed write caches.
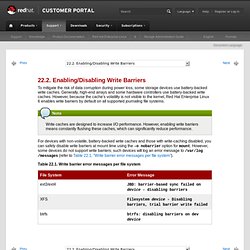
Generally, high-end arrays and some hardware controllers use battery-backed write caches. However, because the cache's volatility is not visible to the kernel, Red Hat Enterprise Linux 6 enables write barriers by default on all supported journaling file systems. Write caches are designed to increase I/O performance. However, enabling write barriers means constantly flushing these caches, which can significantly reduce performance. For devices with non-volatile, battery-backed write caches and those with write-caching disabled, you can safely disable write barriers at mount time using the -o nobarrier option for mount.
Linux, O_SYNC and Write Barriers. Large HDD/SSD Linux 2.6.38 File-System Comparison - Page 2. Write-Cache Enabled? - Jason Brome's Weblog. ... otherwise known as when is a sync() not a sync()?

Recently I ran some performance tests on disk I/O, from both Java and C-based applications. The nature of the applications is such that they require transactional logging for reliability, and therefore need a guarantee that data has been written to disk. After running some simple write tests, I noticed an order of magnitude difference in performance between a couple of machines.
This got me thinking about the impact of disk write synchronization, and what kind of differences would lead to this delta in performance. PRODUCTISE.IN: The Successor to FOSS.IN… Update: Please see this post for updated information about this event This is possibly the fastest that Team FOSS.IN has ever put together an event.
Productise date change. E (programming language) Here is a recursive function for computing the factorial of a number, written in E.
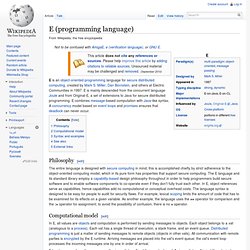
Functions are defined using the def keyword. In the first line, :int is a guard that constrains the argument and result of the function. A guard is not quite the same thing as a type declaration; guards are optional and can specify constraints. The first :int ensures that the body of the function will only have to handle an integer argument. Without the second :int above, the function would not be able to return a value.
Since E is intended to support secure co-operation, the canonical example for E programs is the mint, a simple electronic money system in just a few lines of E. Objects in E are defined with the def keyword, and within the object definition, the to keyword begins each method. The LMAX Architecture. LMAX is a new retail financial trading platform.

As a result it has to process many trades with low latency. The system is built on the JVM platform and centers on a Business Logic Processor that can handle 6 million orders per second on a single thread. The Business Logic Processor runs entirely in-memory using event sourcing. Building Scalable Systems: an Asynchronous Approach. Using A Graph Database To Power The “Web of Things” Neo4j Internals: File Storage.
NOTE: This post is quite outdated, stuff has changed since i wrote this.
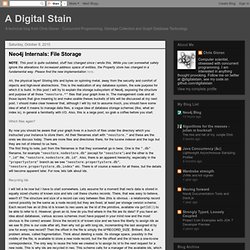
While you can somewhat safely ignore the alterations for increased address space of entities, the Property store has changed in a fundamental way. Please find the new implementation here. Ah, the physical layer! Storing bits and bytes on spinning metal, away from the security and comfort of objects and high-level abstractions.