
Google Drops The Thumbtack Link Penalty Less Than A Week After It Was Issued. Google's Matt Cutts: Web Spam Benefits From Using Rel="Author" A new video by Google’s head of search spam, Matt Cutts, talks about how potentially using rel=”author” structured data can help Google’s Web spam team improve search quality.
Matt Cutts explains that moving from the anonymous Web to a Web with identity helps Google understand the authority and trust of the person writing that content. It can help identify a spammer from an author with a lot of authority and credibility. The example given by Cutts is of our own Founding Editor, Danny Sullivan. If Danny writes something in a low PageRank forum, Google may consider that post written by Danny with more authority, despite the overall domain/forum it was written on having low PageRank. The Ultimate Guide to Multilingual and Multiregional SEO. Link Building eBook by Paddy Moogan. Our Online Reputation Management Playbook. The author's views are entirely his or her own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
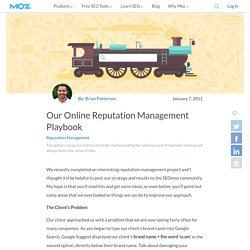
We recently completed an interesting reputation management project and I thought it'd be helpful to post our strategy and results to the SEOmoz community. My hope is that you'll read this and get some ideas, or even better, you'll point out some areas that we overlooked or things we can do to improve our approach. The Client's Problem Our client approached us with a problem that we are now seeing fairly often for many companies. As you began to type our client's brand name into Google Search, Google Suggest displayed our client's brand name + the word 'scam' as the second option, directly below their brand name.
We signed a confidentiality agreement, so I can't say specifically who the client is, but below is a screenshot from another large company, Direct Buy, whom we found experiencing a very similar issue. 10 Dead Simple Tips to Take Advantage of Google+ for SEO. Is freshness an important signal for all sites? 11 Things To Ask Yourself When Optimizing Content. A client asked me the other day why we were optimizing his software for Los Angeles, when he’s located in Raleigh, NC.
In explaining the reason to him, I realized that a basic guideline for optimizing pages is long overdue. I’ve developed the following flow chart and explanation in response. Theming Content The first question you need to ask yourself when optimizing a page is, What is the Page About? If you can’t answer this or your answer is a keyword, then maybe you shouldn’t be building the page. In the case of my client, the page was about a conference in Los Angeles where the company was going to exhibit.
Putting Content Into Context The second question you need to ask yourself is, What is the Purpose of This Page? Is it news, a press release, a blog post, an educational piece, a sales piece? In my client’s case, the goal was to announce that it would be at the event and give a little bit of background about Software A. Consider Content Timing Content Optimization Making Decisions. Yet Another Way to Reclaim Your (not provided) Data. Since Google started rolling out its SSL search for logged-in users, SEOs have been scrambling to find ways to reclaim some of the lost data.
Our industry relies heavily on keyword data gathered by web analytics software. For someone such as myself, who thrives on web analytics data, seeing the accuracy and usefulness of analytics data eroded further causes an almost physical pain. An SEO Playbook For 2012. Search Engine Optimization is growing up.
I am not ready to say the Wild West SEO days are completely eradicated, but in 2011 good search engine optimization is less about trickery and more about engaging content and audience development than ever before. Over the years, quality optimizers have become more prone to avoid technical tricks like using CSS image replacement to inject keyword text or controlling the flow of PageRank by hiding links from search engines. Search engines keep getting better at crawling and indexing. If you are unwilling to burn your website or risk your career, you follow the search engines’ terms of service. Anchor Text - SEO Best Practices. Anchor Text is the visible, clickable text in a hyperlink.
In modern browsers, it is often blue and underlined, such as this link to the moz homepage Code Sample. SEO advice: url canonicalization. (I got my power back!)
Before I start collecting feedback on the Bigdaddy data center, I want to talk a little bit about canonicalization, www vs. non-www, redirects, duplicate urls, 302 “hijacking,” etc. so that we’re all on the same page. Q: What is a canonical url? Do you have to use such a weird word, anyway? A: Sorry that it’s a strange word; that’s what we call it around Google.
Canonicalization is the process of picking the best url when there are several choices, and it usually refers to home pages. Www.example.comexample.com/www.example.com/index.htmlexample.com/home.asp.