
Screen Scraping Script for Kickstarter Projects. Problems with scraping data (with solutions) I’ve written before that I’m using the python library scrapy to get data from Kickstarter to fuel my analysis.

While there are some positives to this decision, there are a few negatives, as well. Here are some I’ve run into recently. Problem 1: You don’t get the whole data set. Or, putting it a little differently, you have to work pretty hard if you want to get the whole data set. In my case, projects only appear on the front page (or the individual category pages) if they’re new, or popular, or highly funded, or staff picks. Solution: Deal with it. At a glance — Scrapy 0.17.0 documentation. Scrapy is an application framework for crawling web sites and extracting structured data which can be used for a wide range of useful applications, like data mining, information processing or historical archival.
Even though Scrapy was originally designed for screen scraping (more precisely, web scraping), it can also be used to extract data using APIs (such as Amazon Associates Web Services) or as a general purpose web crawler. The purpose of this document is to introduce you to the concepts behind Scrapy so you can get an idea of how it works and decide if Scrapy is what you need. When you’re ready to start a project, you can start with the tutorial. Pick a website¶ So you need to extract some information from a website, but the website doesn’t provide any API or mechanism to access that info programmatically.
Let’s say we want to extract the URL, name, description and size of all torrent files added today in the Mininova site. Raw data on Indiegogo. Scraping websites using the Scraper extension for Chrome. Dollar for dollar raised, Kickstarter dominates Indiegogo SIX times over. While freelancing in the crowdfunding space, Edward (@ejunprung) and I noticed a huge size discrepancy between Kickstarter and Indiegogo.
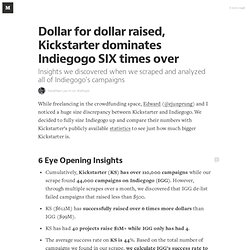
We decided to fully size Indiegogo up and compare their numbers with Kickstarter’s publicly available statistics to see just how much bigger Kickstarter is. 6 Eye Opening Insights Cumulatively, Kickstarter (KS) has over 110,000 campaigns while our scrape found 44,000 campaigns on Indiegogo (IGG). However, through multiple scrapes over a month, we discovered that IGG de-list failed campaigns that raised less than $500.KS ($612M) has successfully raised over 6 times more dollars than IGG ($99M).KS has had 40 projects raise $1M+ while IGG only has had 4.The average success rate on KS is 44%.
Based on the total number of campaigns we found in our scrape, we calculate IGG’s success rate to be 34%. See the full side by side comparison table. Our Thoughts Caveat Methodology See the raw data here. The Untold Story Behind Kickstarter Stats [INFOGRAPHIC] See the full infographic below.
![The Untold Story Behind Kickstarter Stats [INFOGRAPHIC]](http://cdn.pearltrees.com/s/pic/th/untold-kickstarter-infographic-34460159)
A few weeks ago, I wrote about Kickstarter failures that were difficult to find because Kickstarter intentionally prevents failed campaigns from being indexed by the search engines…and how I managed to find (what turned out to be) about 59% of the unsuccessfully funded projects. My article generated a lot of attention, including Mashable and VentureBeat (which republished my post). I’d like to think that it was all this attention that finally led Kickstarter to launch a stats page with data and basic metrics about the projects. I was wrong. Prof. I received much feedback on my article, chief among them from Professor Ethan Mollick of The Wharton School of the University of Pennsylvania. Also, some people objected to my use of the term “failure” on projects that did not get fully funded. Give us some real insights! I heard you loud and clear, so I got in touch with Prof. And don’t think that crowdfunding is a passing fad, either.
Getting it right this time. Allegation: Kickstarter Is Still Hiding Data About Failed Projects [Updated With Corrections] Crowdfunding platform Kickstarter has come in for a lot of plaudits for creating a new platform on which to fund startups. Certainly, since the passing of the U.S. Jobs Act earlier this year, crowdfunding is about to have its day in the sun. But it’s also had its fair share of skeptical critics. [Update: Please scroll to the bottom for a convincing rebuttal by Kickstarter.] A few weeks ago, Jeanne Pi of AppsBlogger wrote about Kickstarter failures that were difficult to find.
However, Pi was criticised for her analysis, by Professor Ethan Mollick of The Wharton School of the University of Pennsylvania, for comparing the percent of projects in a category that are successful without also controlling for the size of the project. So Pi and team have done more digging and come up with some research. . • Pi alleges that the bulk of the missing data about projects is from failed projects. Automated data scraping from websites into Excel. Web scraping. Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites.[1] Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser.
While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying, in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis.