
Bank Marketing Data Set. Source: [Moro et al., 2014] S.

Moro, P. Cortez and P. Rita. A Data-Driven Approach to Predict the Success of Bank Telemarketing. Data Set Information: The data is related with direct marketing campaigns of a Portuguese banking institution. There are four datasets: 1) bank-additional-full.csv with all examples (41188) and 20 inputs, ordered by date (from May 2008 to November 2010), very close to the data analyzed in [Moro et al., 2014]2) bank-additional.csv with 10% of the examples (4119), randomly selected from 1), and 20 inputs.3) bank-full.csv with all examples and 17 inputs, ordered by date (older version of this dataset with less inputs). 4) bank.csv with 10% of the examples and 17 inputs, randomly selected from 3 (older version of this dataset with less inputs).
The classification goal is to predict if the client will subscribe (yes/no) a term deposit (variable y). Attribute Information: Output variable (desired target): 21 - y - has the client subscribed a term deposit? S. S. Glass Identification Data Set. Iris Data Set. Algorithme des k voisins les plus proches. Lors de cette séquence, on découvrira l’algorithme des K voisins les plus proches en anglais, K Nearest Neighbors (K-NN).

Il s’agit d’un algorithme d’apprentissage supervisé. Il sert aussi bien pour la classification que la régression. Ainsi, nous allons voir le fonctionnement de cet algorithme, ses caractéristiques et comment il parvient à établir des prédictions. C’est parti ! Semaine 3-Premières NSI - Algo des k plus proches voisins 2 - Lycée de la Méditerranée. NSI : Numérique et Sciences Informatiques - Algorithmie. KNN. Algorithme des k voisins les plus proches (KNN) Cet algorithme peut être mis en oeuvre au travers de l'activité patisserie.

K plus proches voisins - exercices. Trouver la classe avec les k plus proches voisins Supposons que l’on a un problème de classification qui consiste à déterminer la classe d’appartenance de nouvelles instances .

Le domaine de valeurs des classes possibles est . Selon la base de connaissance suivante, déterminez à la main (ou à l’aide d’un tableur) la classe de l’instance , dont les valeurs pour les attributs numériques à sont , à l’aide de l’algorithme des k-voisins les plus proches (K-NN) avec puis . Montrez tous les calculs. Autre exemple simple Soit les points de coordonnées suivantes :
Numérique et sciences informatiques - Algorithme des k plus proches voisins. Considérons le jeu de données suivant : Un nouveau client se présente et on souhaite estimer sa fidélité...
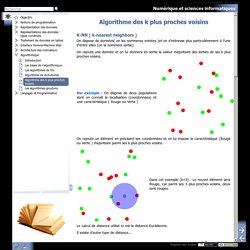
Pour cela, on utilise un algorithme K-NN On calcule la distance de David avec chacun des autres clients Par exemple : d(David, Jean)= Et ainsi de suite : On obtient les distances suivantes : [('Louis', 15.0), ('Jean', 15.165750503540039), ('Nicolas', 15.748015403747559), ('Suzanne', 122.00409698486328), ('Anne', 152.2399444580078)] Algorithme des k plus proches voisins. Dans ce chapitre nous abordons un algorithme dit d’apprentissage automatique qui permet à un programme d’apprendre à classer des « objets » en utilisant un jeu de données pour qu’il y trouve des similarités.

C’est un algorithme simple de « machine learning » un sujet très en vogue à l’heure actuelle dans le domaine de l’informatique. Principe Principe de l'apprentissage supervisé A l'heure actuelle, l'intelligence artificielle se base souvent sur l'utilisation de données annotées que l'on fournit à l'ordinateur pour qu'il y trouve des similarités(c'est ce que l'on appele de l'apprentissage supervisé).
On peut fournir à un programme une grande quantité d'écritures de chiffres. Le programme va lire toutes les données, et grâce à des algorithmes plus ou moins évolués, le programme va trouver les points communs entre les chiffres représentant le même nombre. Ensuite, on peut donner au programme une image non annotée, et il nous dira s'il s'agit d'un 1, d'un 6 ou d'un 8... NSI Algorithme des k plus proches voisins. L'idée d'apprentissage automatique (machine learning) est réellement née en 1936 avec le concept de machine universelle d'Alan Turing et de son article de 1950 sur le test de turing.

En 1943 deux chercheurs représentent le fonctionnement des neurones avec des circuits électriques, c'est le début de la théorie sur les réseaux neuronaux. En 1952 Arthur Samuel écrit un programme capable de s'améliorer en jouant aux dames. Depuis les progrès ne font que continuer et le machine learning est probablement le secteur de l'informatique le plus en expansion (reconnaissance faciale, conduite automatique, création de vaccins, aide à la prise de décision (data scientist),...). Il existe dans ce domaine, différentes approches qu'il est intéressant de connaitre: Apprentissage supervisé: on a des exemples que l'on sait classer et qui sont déjà classées.
Algorithme KNN : algorithme des $k$ plus proches voisins. Demandez le programme !

(28) Comprendre le Machine Learning: L'algorithme du KNN. (28) Intelligence Artificielle [12.3] : Apprentissage automatique - k plus proches voisins. (28) NSI Spécialité première : K plus proche voisins application algo de recommandation 3/3. Machine Learning : l'algorithme des k plus proches voisins. Classification à l’aide des plus proches voisins — Machine Learning, Statistiques et Programmation. La figure suivante représente un problème de classification classique.
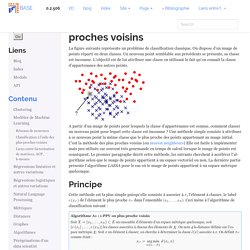
On dispose d’un nuage de points réparti en deux classes. Un nouveau point semblable aux précédents se présente, sa classe est inconnue. L’objectif est de lui attribuer une classe en utilisant le fait qu’on connaît la classe d’appartenance des autres points. A partir d’un nuage de points pour lesquels la classe d’appartenance est connue, comment classer un nouveau point pour lequel cette classe est inconnue ? Une méthode simple consiste à attribuer à ce nouveau point la même classe que le plus proche des points appartenant au nuage initial. B+ tree Ce premier algorithme B+ tree s’applique dans le cas réel afin d’ordonner des nombres dans un arbre de sorte que chaque noeud ait un père et pas plus de fils.
Cet arbre permet de trier une liste de nombres, c’est une généralisation du tri quicksort pour lequel . Éléments), le coût de l’algorithme est en R-tree ou Rectangular Tree fils. . Désigne son volume. Non feuille, for n in. p178. Bien comprendre l’algorithme des K-plus proches voisins (Fonctionnement et implémentation sur R et Python) : La méthode des “k plus proches voisins” fait partie des méthodes les plus simples d’apprentissage supervisé pouvant être utilisée pour les cas de régression et de classification.
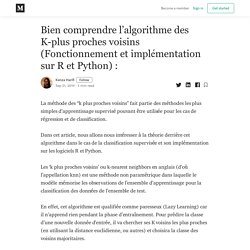
Dans cet article, nous allons nous intéresser à la théorie derrière cet algorithme dans le cas de la classification supervisée et son implémentation sur les logiciels R et Python. 2 - Méthode des k plus proches voisins. Adrien Guille, Université Lyon 2 Partie théorique Formulation du modèle Partie pratique Formulation du modèle Soit le jeu de données composé de paires , avec la description d'un individu selon descripteurs, sous la forme d'un vecteur réel de taille , et la classe d'appartenance de cet individu parmi classes possibles : L'espace de représentation des observations doit être muni d'une distance, nécessaire à la construction du voisinage d’une nouvelle observation.
Algorithme des k plus proches voisins. Nous allons maintenant travailler sur un algorithme d'apprentissage automatique, souvent appelé, même en français, algorithme de machine learning. L'idée est d'utiliser un grand nombre de données afin "d'apprendre à la machine" à résoudre un certain type de problème (nous verrons un exemple un peu plus loin). Cette idée d'apprentissage automatique ne date pas d'hier, puisque le terme de machine learning a été utilisé pour la première fois par l'informaticien américain Arthur Samuel en 1959.
Pourquoi le machine learning est tant "à la mode" depuis quelques années ? Simplement parce que le nerf de la guerre dans les algorithmes de machine learning est la qualité et la quantité des données (les données qui permettront à la machine d'apprendre à résoudre un problème), or, avec le développement d'internet, il est relativement simple de trouver des données sur n'importe quel sujet (on parle de "big data"). Pour chaque iris étudié, Anderson a mesuré (en cm) : Méthode des k plus proches voisins. Méthode des k plus proches voisins En intelligence artificielle, plus précisément en apprentissage automatique, la méthode des k plus proches voisins est une méthode d’apprentissage supervisé. En abrégé k-NN ou KNN, de l'anglais k-nearest neighbors. Dans ce cadre, on dispose d’une base de données d'apprentissage constituée de N couples « entrée-sortie ». Pour estimer la sortie associée à une nouvelle entrée x, la méthode des k plus proches voisins consiste à prendre en compte (de façon identique) les k échantillons d'apprentissage dont l’entrée est la plus proche de la nouvelle entrée x, selon une distance à définir.
Par exemple, dans un problème de classification, on retiendra la classe la plus représentée parmi les k sorties associées aux k entrées les plus proches de la nouvelle entrée x. Recherche des plus proches voisins. Un article de Wikipédia, l'encyclopédie libre. La recherche des plus proches voisins, ou des k plus proches voisins, est un problème algorithmique classique. De façon informelle le problème consiste, étant donné un point à trouver dans un ensemble d'autres points, quels sont les k plus proches. Exemple de recherche d'un voisinage de taille 3 autour d'une coordonnée donnée (D = 1, k = 3). Définition[modifier | modifier le code] Un cas classique est celui de la recherche du plus proche voisin, c'est-à-dire le cas k=1. Méthodes exactes[modifier | modifier le code] Recherche linéaire[modifier | modifier le code] L'algorithme naïf de recherche de voisinage consiste à passer sur l'ensemble des n points de A et à regarder si ce point est plus proche ou non qu'un des plus proches voisins déjà sélectionné, et si oui, l'insérer.
Algorithme des k plus proches voisins.