
陳雲濤的部落格: [筆記] 平行計算 Ch1 名詞解釋與比較. 缓存一致性(Cache Coherency)入门. 本文是RAD Game Tools程序员Fabian “ryg” Giesen在其博客上发表的《Cache coherency primer》一文的翻译,经作者许可分享至InfoQ中文站。
该系列共有两篇,本文系第一篇。 我计划写一些关于多核场景下数据组织的文章。 写了第一篇,但我很快意识到有大量的基础知识我首先需要讲一下。 在本文中,我就尝试阐述这些知识。 缓存(Cache) 本文是关于CPU缓存的快速入门。 在现代的CPU(大多数)上,所有的内存访问都需要通过层层的缓存来进行。 CPU的读/写(以及取指令)单元正常情况下甚至都不能直接访问内存——这是物理结构决定的;CPU都没有管脚直接连到内存。 缓存是分“段”(line)的,一个段对应一块存储空间,大小是32(较早的ARM、90年代/2000年代早期的x86和PowerPC)、64(较新的ARM和x86)或128(较新的Power ISA机器)字节。 当CPU看到一条读内存的指令时,它会把内存地址传递给一级数据缓存(或可戏称为L1D$,因为英语中“缓存(cache)”和“现金(cash)”的发音相同)。 如果我们只处理读操作,那么事情会很简单,因为所有级别的缓存都遵守以下规律,我称之为: 基本定律:在任意时刻,任意级别缓存中的缓存段的内容,等同于它对应的内存中的内容。 一旦我们允许写操作,事情就变得复杂一点了。 回写模式就有点复杂了。 回写定律:当所有的脏段被回写后,任意级别缓存中的缓存段的内容,等同于它对应的内存中的内容。 换句话说,回写模式的定律中,我们去掉了“在任意时刻”这个修饰语,代之以弱化一点的条件:要么缓存段的内容和内存一致(如果缓存段是干净的话),要么缓存段中的内容最终要回写到内存中(对于脏缓存段来说)。 直接模式更简单,但是回写模式有它的优势:它能过滤掉对同一地址的反复写操作,并且,如果大多数缓存段都在回写模式下工作,那么系统经常可以一下子写一大片内存,而不是分成小块来写,前者的效率更高。
有些(大多数是比较老的)CPU只使用直写模式,有些只使用回写模式,还有一些,一级缓存使用直写而二级缓存使用回写。 一致性协议(Coherency protocols) 只要系统只有一个CPU核在工作,一切都没问题。 好吧,答案很简单:什么也不会发生。 注意,这个问题的根源是我们拥有多组缓存,而不是多个CPU核。 这本身没问题。 MESI以及衍生协议 内存模型. 平行計算ch2筆記 Directory-based Protocol. 本系列是 Parallel Programming in C with MPI and OpenMP 這本書的讀書心得!
上篇前情提要: Multiprocessor 兩種:Centralized Multiprocessor 與 Distributed Multiprocessor Centralized Multiprocessor :直接把Uniprocessor做擴充! 直接把CPU掛到bus上! 不管哪一個CPU處理去連記憶體都一樣快! 這個架構在處理Cache coherence(快取一致性)的機制為 Write Invalidate Protocol,其運作的內容於上一篇詳細介紹過. Symmetric multiprocessor system. A symmetric multiprocessor system (SMP) is a multiprocessor system with centralized shared memory called main memory (MM) operating under a single operating system with two or more homogeneous processors—i.e., it is not a heterogeneous computing system.
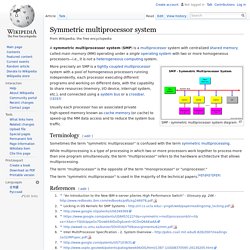
SMP - symmetric multiprocessor system diagram More precisely an SMP is a tightly coupled multiprocessor system with a pool of homogeneous processors running independently, each processor executing different programs and working on different data, with the capability to share resources (memory, I/O device, interrupt system, etc.), and connected using a system bus or a crossbar.[1][2][3] Usually each processor has an associated private high-speed memory known as cache memory (or cache) to speed-up the MM data access and to reduce the system bus traffic. Terminology[edit] Sometimes the term "symmetric multiprocessor" is confused with the term symmetric multiprocessing. Multiprocessing. According to some on-line dictionaries, a multiprocessor is a computer system having two or more processing units (multiple processors) each sharing main memory and peripherals, in order to simultaneously process programs.[4][5] A 2009 textbook defined multiprocessor system similarly, but noting that the processors may share "some or all of the system’s memory and I/O facilities"; it also gave tightly coupled system as a synonymous term.[6] In Flynn's taxonomy, multiprocessors as defined above are MIMD machines.[10][11] As they are normally construed to be tightly coupled (share memory), multiprocessors are not the entire class of MIMD machines, which also contains message passing multicomputer systems.[10]
Memory management unit. A memory management unit (MMU), sometimes called paged memory management unit (PMMU), is a computer hardware unit having all memory references passed through itself, primarily performing the translation of virtual memory addresses to physical addresses.
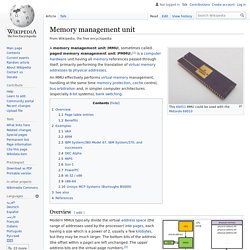
It is usually implemented as part of the central processing unit (CPU), but it also can be in the form of a separate integrated circuit. Overview[edit] Schematic of the operation of an MMU[1]:186 ff. Page table entries[edit] Most MMUs use an in-memory table of items called a "page table", containing one "page table entry" (PTE) per page, to map virtual page numbers to physical page numbers in main memory. Hardware/Software Codesign Group.
Cache coherence. An illustration showing multiple caches of some memory, which acts as a shared resource In the illustration on the right, if the client on the top has a copy of a memory block from a previous read and the client on the bottom changes that memory block, the client on the top could be left with an invalid cache of memory without any notification of the change.
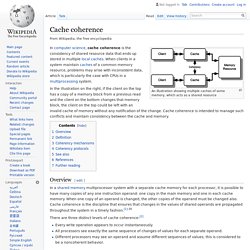
Cache coherence is intended to manage such conflicts and maintain consistency between the cache and memory. CPU cache. All modern (fast) CPUs (with few specialized exceptions[2]) have multiple levels of CPU caches.
The first CPUs that used a cache had only one level of cache; unlike later level 1 caches, it was not split into L1d (for data) and L1i (for instructions). Almost all current CPUs with caches have a split L1 cache. They also have L2 caches and, for larger processors, L3 caches as well. The L2 cache is usually not split and acts as a common repository for the already split L1 cache. Every core of a multi-core processor has a dedicated L2 cache and is usually not shared between the cores. Other types of caches exist (that are not counted towards the "cache size" of the most important caches mentioned above), such as the translation lookaside buffer (TLB) that is part of the memory management unit (MMU) that most CPUs have. Overview[edit] When trying to read from or write to a location in main memory, the processor checks whether the data from that location is already in the cache.
牛的大腦-caching.