
Pig as Hadoop Connector, Part One: Pig, MongoDB and Node.js. Series Introduction Apache Pig is a dataflow oriented, scripting interface to Hadoop.

Pig enables you to manipulate data as tuples in simple pipelines without thinking about the complexities of MapReduce. But Pig is more than that. Pig has emerged as the ‘duct tape’ of Big Data, enabling you to send data between distributed systems in a few lines of code. In this series, we’re going to show you how to use Hadoop and Pig to connect different distributed systems, to enable you to process data from wherever and to wherever you like. Working code for this post as well as setup instructions for the tools we use are available at and you can download the Enron emails we use in the example in Avro format at You can run our example Pig scripts in local mode (without Hadoop) with the -x local flag: pig -x local.
Part two of this series on HBase and JRuby is available here: Introduction Pig and Avro. MapReduce Patterns, Algorithms, and Use Cases « Highly Scalable Blog. In this article I digested a number of MapReduce patterns and algorithms to give a systematic view of the different techniques that can be found on the web or scientific articles.
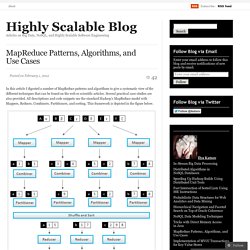
Several practical case studies are also provided. All descriptions and code snippets use the standard Hadoop’s MapReduce model with Mappers, Reduces, Combiners, Partitioners, and sorting. This framework is depicted in the figure below. MapReduce Framework Counting and Summing Problem Statement: There is a number of documents where each document is a set of terms. Solution: Let start with something really simple. The obvious disadvantage of this approach is a high amount of dummy counters emitted by the Mapper. In order to accumulate counters not only for one document, but for all documents processed by one Mapper node, it is possible to leverage Combiners: Applications: Log Analysis, Data Querying Collating Problem Statement: There is a set of items and some function of one item. Ted Dunning on Twitter's Storm, 1/3. Welcome to Apache Avro! Products - Nube Technologies. Welcome to Apache™ Hadoop™! Database Access with Hadoop.
Editor’s note (added Nov. 9. 2013): Valuable data in an organization is often stored in relational database systems.

To access that data, you could use external APIs as detailed in this blog post below, or you could use Apache Sqoop, an open source tool (packaged inside CDH) that allows users to import data from a relational database into Apache Hadoop for further processing. Sqoop can also export those results back to the database for consumption by other clients. Apache Hadoop’s strength is that it enables ad-hoc analysis of unstructured or semi-structured data. Relational databases, by contrast, allow for fast queries of very structured data sources. A point of frustration has been the inability to easily query both of these sources at the same time.
This blog post explains how the DBInputFormat works and provides an example of using DBInputFormat to import data into HDFS. DBInputFormat and JDBC First we’ll cover how DBInputFormat interacts with databases. Configuring the job Resources. Introducing Cascalog: a Clojure-based query language for Hadoop. I'm very excited to be releasing Cascalog as open-source today.

Cascalog is a Clojure-based query language for Hadoop inspired by Datalog. Highlights Simple - Functions, filters, and aggregators all use the same syntax. Joins are implicit and natural.Expressive - Logical composition is very powerful, and you can run arbitrary Clojure code in your query with little effort.Interactive - Run queries from the Clojure REPL.Scalable - Cascalog queries run as a series of MapReduce jobs.Query anything - Query HDFS data, database data, and/or local data by making use of Cascading's "Tap" abstractionCareful handling of null values - Null values can make life difficult.
OK, let's jump into Cascalog and see what it's all about! Basic queries First, let's start the REPL and load the playground: lein repluser=> (use 'cascalog.playground) (bootstrap) This will import everything we need to run the examples. User=> (? This query can be read as "Find all ? OK, let's try something more involved. User=> (? (age ? Storm, distributed and fault-tolerant realtime computation. Nathanmarz/storm.