
Viterbi algorithm. The Viterbi algorithm is a dynamic programming algorithm for finding the most likely sequence of hidden states – called the Viterbi path – that results in a sequence of observed events, especially in the context of Markov information sources and hidden Markov models.
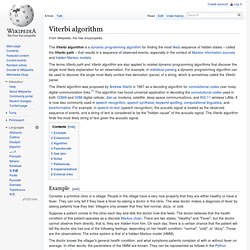
The terms Viterbi path and Viterbi algorithm are also applied to related dynamic programming algorithms that discover the single most likely explanation for an observation. For example, in statistical parsing a dynamic programming algorithm can be used to discover the single most likely context-free derivation (parse) of a string, which is sometimes called the Viterbi parse. Example[edit] Consider a primitive clinic in a village. People in the village have a very nice property that they are either healthy or have a fever. Suppose a patient comes to the clinic each day and tells the doctor how she feels. The function viterbi takes the following arguments: obs is the sequence of observations, e.g.
Extensions[edit] to state . . If. Bloom filter. Bloom proposed the technique for applications where the amount of source data would require an impracticably large hash area in memory if "conventional" error-free hashing techniques were applied.
He gave the example of a hyphenation algorithm for a dictionary of 500,000 words, out of which 90% follow simple hyphenation rules, but the remaining 10% require expensive disk accesses to retrieve specific hyphenation patterns. With sufficient core memory, an error-free hash could be used to eliminate all unnecessary disk accesses; on the other hand, with limited core memory, Bloom's technique uses a smaller hash area but still eliminates most unnecessary accesses. For example, a hash area only 15% of the size needed by an ideal error-free hash still eliminates 85% of the disk accesses (Bloom (1970)).
More generally, fewer than 10 bits per element are required for a 1% false positive probability, independent of the size or number of elements in the set (Bonomi et al. (2006)). . . . As before. Modern Information Retrieval - Porter's Algorithm. The rules in the Porter algorithm are separated into five distinct phases numbered from 1 to 5.

They are applied to the words in the text starting from phase 1 and moving on to phase 5. Further, they are applied sequentially one after the other as commands in a program. Thus, in the immediately following, we specify the Porter algorithm in a pseudo programming language whose commands take the form of rules for suffix substitution (as above). This pseudo language adopts the following (semi-formal) conventions: Thus, the expression (C)* refers to a sequence of zero or more consonants while the expression ((V)*(C)*)* refers to a sequence of zero or more vowels followed by zero or more consonants which can appear zero or more times. If (*V*L) then ed 2#21#1 states that the substitution of the suffix ed by nil (i.e., the removal of the suffix ed) only occurs if the current word contains a vowel and at least one additional letter. sses 2#2 ss; ies 2#2 i; ss 2#2 ss; s 2#2 1#1; }