
Creer un ebook (OCR, biblithèque en ligne) Textract, le nouvel extracteur de texte et de données d’Amazon. AWS (Amazon Web Services) a annoncé récemment l’arrivée du tout nouveau Textract.

Plus qu’un simple logiciel d’OCR (reconnaissance optique de caractères), Textract permet d’extraire du texte et des données de n’importe quel type de document. En effet, Textract peut extraire non seulement du texte, mais aussi des données dans des tableaux, ou dans des formulaires, y compris depuis des documents scannés. Il génère ensuite des données structurées sans aucune intervention humaine. Par exemple, Textract peut transformer un document PDF en feuille de calcul, en lisant, extrayant et structurant les différentes données chiffrées.
Selon AWS : « Amazon Textract détecte automatiquement la mise en page d’un document et les éléments clés de la page, comprend les relations de données dans les formulaires ou les tableaux incorporés et extrait tout avec son contexte intact. Concrètement, Textract utilise le machine learning pour reconnaître les informations à extraire. Où en est le projet ReLIRE ? Dès son lancement, en 2012, nous vous parlions de ReLIRE, ce projet ambitieux de numérisation massive des ouvrages indisponibles du XXe siècle initié par la BnF.

Suite à une conférence donnée dans le cadre de l’édition 2018 du DPUB Summit en mai dernier, nous revenons six ans plus tard sur sa genèse et son fonctionnement, mais aussi sur les difficultés rencontrées depuis sa création. Des livres inégaux face à la numérisation Il semble aujourd’hui difficilement concevable pour les éditeurs de ne pas prévoir, en parallèle de l’impression papier, une version numérique des ouvrages publiés. Cependant, qu’en est-il de ces ouvrages non réédités, publiés avant les années 2000 et l’avènement des nouvelles technologies ?
Selon Virginie Clayssen, directrice en charge de l’innovation chez Editis et présidente d’EDRLab, il existe en fait trois cas de figure quant à la potentielle numérisation des ouvrages, en fonction de leur date de publication. Le processus de numérisation se fait en deux étapes : L'aventure du livre - Arrêt sur. La numérisation des livres La conversion numérique d’un livre, ou numérisation, peut s’opérer de deux manières : en mode texte ou en mode image.
Le mode texte consiste à obtenir depuis un support papier un texte électronique que l’on peut réutiliser par copier-coller, par exemple, ou qui peut alimenter des bases de données ou des moteurs de recherche. Ceux-ci indexeront chaque mot, c’est-à-dire qu’il sera possible, de façon automatique, de retrouver dans le texte les occurrences de tel ou tel terme. La numérisation en mode texte peut résulter d’une saisie manuelle. Dans ce cas, un opérateur, salarié ou bénévole, recopie le texte du livre sur un logiciel de traitement de texte. Astuce : récupérer les pages d’un livre présent dans Google Books (mode aperçu) Voici un tutoriel présentant plusieurs manières de télécharger une page/plusieurs pages d’un livre consultable en mode aperçu dans Google Books.
L’astuce fonctionne également pour les ouvrages disponibles en lecture intégrale (domaine public), bien qu’elle soit dans ce cas-là moins utile car vous pouvez déjà télécharger le livre en PDF. Plan du billet (liens cliquables) : Présentation Pierre-Carl Langlais a écrit en 2014 un billet expliquant comment lire l’intégralité d’un ouvrage disponible en mode aperçu dans Google Books. Google Books et la numérisation incomplète. Depuis plusieurs années, je suis devenu un utilisateur régulier des bibliothèques numériques que sont Gallica, Internet Archive et Google Books.
Je recherche en particulier des ouvrages illustrés faisant partie du domaine public : récits et guides de voyages, albums pittoresques, revues de géographie, atlas… Je dois bien le reconnaître : Google Books m’est très utile dans le cadre de mes recherches. Le nombre d’ouvrages numérisés est impressionnant et une bonne partie de mon corpus de thèse est constitué de guides de voyage du XIXe siècle disponibles sur ce site web. Dans ce billet, je souhaite cependant mettre l’accent sur les inconvénients de cette bibliothèque numérique, dont certains invitent à une réflexion profonde quant aux conditions et choix de numérisation. Note : Cliquer sur les images pour les ouvrir en grand (nouvel onglet) Fr14 user guide french.
ABBYY FineReader 15 - Fonctionnalités PDF et OCR pour plus de productivité. 's K2pdfopt. OVERVIEW K2pdfopt optimizes PDF/DJVU files for mobile e-readers (e.g. the Kindle) and smartphones.
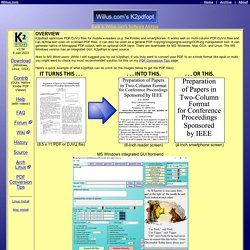
It works well on multi-column PDF/DJVU files and can re-flow text even on scanned PDF files. It can also be used as a general PDF copying/cropping/re-sizing/OCR-ing manipulation tool. It can generate native or bitmapped PDF output, with an optional OCR layer. There are downloads for MS Windows, Mac OSX, and Linux. The MS Windows version has an integrated GUI. Note to MS Word users: Before using k2pdfopt on your PDF file you might want to check my most recommended solution on my PDF Conversion Tips page. Here's a quick example of what k2pdfopt can do (click on the images below to get the PDF files): LATEST NEWS.