
How to Analyze Highly Dynamic Datasets with Apache Drill. Today’s data is dynamic and application-driven.
The growth of a new era of business applications driven by industry trends such as web/social/mobile/IOT are generating datasets with new data types and new data models. These applications are iterative, and the associated data models typically are semi-structured, schema-less and constantly evolving. Semi-structured where an element can be complex/nested, and schema-less with its ability to allow varying fields in every single row and constantly evolving where fields get added and removed frequently to meet business requirements.
In other words, the modern datasets are not only about volume and velocity, but also about variety and variability. Apache Drill, the industry’s first schema-free SQL engine for Hadoop and NoSQL, allows business users to natively query dynamic datasets such as JSON in a self-service fashion using familiar SQL skillsets and BI tools. Let me demonstrate this with a quick example. Bin/sqlline -u jdbc:drill:zk=local. The Log: What every software engineer should know about real-time data's unifying abstraction. I joined LinkedIn about six years ago at a particularly interesting time.
We were just beginning to run up against the limits of our monolithic, centralized database and needed to start the transition to a portfolio of specialized distributed systems. This has been an interesting experience: we built, deployed, and run to this day a distributed graph database, a distributed search backend, a Hadoop installation, and a first and second generation key-value store. One of the most useful things I learned in all this was that many of the things we were building had a very simple concept at their heart: the log. Sometimes called write-ahead logs or commit logs or transaction logs, logs have been around almost as long as computers and are at the heart of many distributed data systems and real-time application architectures.
Part One: What Is a Log? A log is perhaps the simplest possible storage abstraction. Records are appended to the end of the log, and reads proceed left-to-right. What's next. Questioning the Lambda Architecture. Nathan Marz wrote a popular blog post describing an idea he called the Lambda Architecture (“How to beat the CAP theorem“).
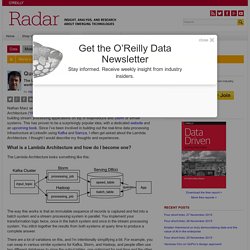
The Lambda Architecture is an approach to building stream processing applications on top of MapReduce and Storm or similar systems. This has proven to be a surprisingly popular idea, with a dedicated website and an upcoming book. Since I’ve been involved in building out the real-time data processing infrastructure at LinkedIn using Kafka and Samza, I often get asked about the Lambda Architecture. I thought I would describe my thoughts and experiences. Lambda Architecture » λ lambda-architecture.net. What No One Tells You About Real-Time Machine Learning. Real-time machine learning has access to a continuous flow of transactional data, but what it really needs in order to be effective is a continuous flow of labeled transactional data, and accurate labeling introduces latency.
By Dmitry Petrov, Microsoft and FullStackML. During this year, I heard and read a lot about real-time machine learning. People usually provide this appealing business scenario when discussing credit card fraud detection systems. They say that they can continuously update credit card fraud detection model in real-time (See “What is Apache Spark?” , “…real-time use cases…” and “Real time machine learning”). Machine learning process Creating labeled data is probably the slowest and the most expensive step in most of the machine learning systems. 1.
For training credit card models, you need a lot of examples of transactions and each transaction should be labeled as Fraud or Not-Fraud. The labeled data set plays a central role in this process. 2. 3. Conclusion Original. Patterns for Streaming Realtime Analytics. Design patterns are well-known for solving the recurrent problems in software engineering, on similar lines we can have Streaming Realtime Analytics patterns and avoid reinventing the wheel.

Here, you can see the major patterns we found out for it. By Srinath Perera (Director, Research, WSO2 Inc.) Stream processing technologies like Apache Samza and Apache Storm has received much attention under the theme large scale streaming analytics. However, these tools force every programmer to design and implement real-time analytics processing from first principals. For an example, if users need a time window, they need to implement it from first principals.