
Palantir, the War on Terror's Secret Weapon. In October, a foreign national named Mike Fikri purchased a one-way plane ticket from Cairo to Miami, where he rented a condo.
Over the previous few weeks, he’d made a number of large withdrawals from a Russian bank account and placed repeated calls to a few people in Syria. More recently, he rented a truck, drove to Orlando, and visited Walt Disney World by himself. As numerous security videos indicate, he did not frolic at the happiest place on earth. He spent his day taking pictures of crowded plazas and gate areas.
MapReduce: A Flexible Data Processing Tool. By Jeffrey Dean, Sanjay Ghemawat Communications of the ACM, Vol. 53 No. 1, Pages 72-77 10.1145/1629175.1629198 Comments (3) Mapreduce is a programming model for processing and generating large data sets.4 Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs and a reduce function that merges all intermediate values associated with the same intermediate key.
We built a system around this programming model in 2003 to simplify construction of the inverted index for handling searches at Google.com. Since then, more than 10,000 distinct programs have been implemented using MapReduce at Google, including algorithms for large-scale graph processing, text processing, machine learning, and statistical machine translation. the Hadoop open source implementation of MapReduce has been used extensively outside of Google by a number of organizations.10,11 Back to Top Compared to Parallel Databases. The Dangers of Overfitting or How to Drop 50 spots in 1 minute. This post was originally published on Gregory Park's blog . Reprinted with permission from the author (thanks Gregory!) CS345A: Data Mining. Course Info | Handouts | Assignments | Project | Course Outline | Resources and Reading NEW NEW ROOM: 200-002.

This is the big auditorium in the basement of the History Corner. It seats 163, so there should be plenty of room for us to spread out. Instructors: Anand Rajaraman (anand @ kosmix dt com), Jeffrey D. Ullman (ullman @ gmail dt com). TA: Anish Johnson (ajohna @ stanford dt edu). Staff Mailing List: cs345a-win0809-staff@mailman.stanford.edu. How Vertica Was the Star of the Obama Campaign, and Other Revelations. The 2012 Obama re-election campaign has important implications for organizations that want to make better use of big data.

The hype about its use of data is certainly justified, but a lesser-noticed aspect of the campaign ran against another kind of data hype we’ve all heard: the Silicon Valley hype around Hadoop that goes too far and claims an unreasonably large role for Hadoop. One of the most critical contributors to the Obama campaign’s success was the direct access it had to a massive database of voter data stored in Vertica. The Reality Club: THE END OF THEORY. There's a dawning sense that extremely large databases of information, starting in the petabyte level, could change how we learn things.

The traditional way of doing science entails constructing a hypothesis to match observed data or to solicit new data. Here's a bunch of observations; what theory explains the data sufficiently so that we can predict the next observation? It may turn out that tremendously large volumes of data are sufficient to skip the theory part in order to make a predicted observation. Google was one of the first to notice this. For instance, take Google's spell checker. Instead Google operates a very large dataset of observations which show that for any given spelling of a word, x number of people say "yes" when asked if they meant to spell word "y. " Google's spelling engine consists entirely of these datapoints, rather than any notion of what correct English spelling is. The End of Theory: The Data Deluge Makes the Scientific Method Obsolete. Deja VVVu: Others Claiming Gartner’s Construct for Big Data.
What is data science? We’ve all heard it: according to Hal Varian, statistics is the next sexy job.
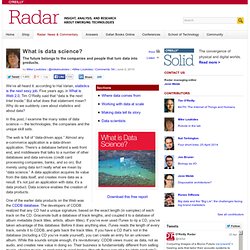
The Data Science Venn Diagram — Drew Conway. On Monday I—humbly—joined a group of NYC's most sophisticated thinkers on all things data for a half-day unconference to help O'Reily organize their upcoming Strata conference.

The break out sessions were fantastic, and the number of people in each allowed for outstanding, expert driven, discussions. One of the best sessions I attended focused on issues related to teaching data science, which inevitably led to a discussion on the skills needed to be a fully competent data scientist. L'Aquila quake: Italy scientists guilty of manslaughter. 22 October 2012Last updated at 15:06 ET The BBC's Alan Johnston in Rome says the prosecution argued that the scientists were "just too reassuring" Six Italian scientists and an ex-government official have been sentenced to six years in prison over the 2009 deadly earthquake in L'Aquila.

A regional court found them guilty of multiple manslaughter. United States. Google Flu Trends Wildly Overestimated This Year's Flu Outbreak - David Wagner. Scientific hindsight shows that Google Flu Trends far overstated this year's flu season, raising questions about the accuracy of using a search engine, which Google and the media hyped as an efficient public health tool, to accurately monitor the flu.

Nature's Declan Butler reported today on the huge discrepancy between Google Flu Trend's estimated peak flu levels and data collected by the U.S. Centers for Disease Control and Prevention (CDC) earlier this winter. Google bases their numbers on flu-related searches (the basic idea being that more people Googling terms like "flu symptoms" equals more people catching viruses). The CDC, on the other hand, uses traditional epidemiological surveillance methods.
Past results have shown Google to have a pretty good track record on mirroring CDC flu charts. The Expression of Emotions in 20th Century Books. We report here trends in the usage of “mood” words, that is, words carrying emotional content, in 20th century English language books, using the data set provided by Google that includes word frequencies in roughly 4% of all books published up to the year 2008.

We find evidence for distinct historical periods of positive and negative moods, underlain by a general decrease in the use of emotion-related words through time. Finally, we show that, in books, American English has become decidedly more “emotional” than British English in the last half-century, as a part of a more general increase of the stylistic divergence between the two variants of English language. Figures Citation: Acerbi A, Lampos V, Garnett P, Bentley RA (2013) The Expression of Emotions in 20th Century Books. Latent Semantic Analysis in Python. Latent Semantic Analysis (LSA) is a mathematical method that tries to bring out latent relationships within a collection of documents.

Rather than looking at each document isolated from the others it looks at all the documents as a whole and the terms within them to identify relationships. An example of LSA: Using a search engine search for “sand”. Documents are returned which do not contain the search term “sand” but contains terms like “beach”. LSA has identified a latent relationship, “sand” is semantically close to “beach”. Whom the Gods Would Destroy, They First Give Real-time Analytics. Homer: There's three ways to do things. The right way, the wrong way, and the Max Power way! Bart: Isn't that the wrong way? Pat Hanrahan - Tools for Data Enthusiasts. The Joy of Stats. About the video Hans Rosling says there’s nothing boring about stats, and then goes on to prove it. A one-hour long documentary produced by Wingspan Productions and broadcast by BBC, 2010. A DVD is available to order from Wingspan Productions.
Director & Producer; Dan Hillman, Executive Producer: Archie Baron. ©Wingspan Productions for BBC, 2010. IEEE Conference on Data Mining. [April 22, 2009:] A companion book on The Top Ten Algorithms in Data Mining published in April 2009 [December 24, 2007:] A companion article in PDF for this top-10 algorithm initiative:Xindong Wu, Vipin Kumar, J.