
Empêcher l'indexation d'1 site par les moteurs de recherche. Les Crawlers. Les crawlers Un crawler est un robot (aussi appelé bot ou spider ) qui parcourt le web et récupère automatiquement les pages web visitées. Les moteurs de recherche ont donc des crawlers qui se chargent de ce travail d’indexation. Le crawler de Google s’appelle GoogleBot alors que celui de Yahoo s’appelle Yahoo Slurp . A chaque fois qu’un crawler visite une page web, il en fait l’analyse, en extrait les liens vers d’autres pages web et les indexe dans sa base de données. Connaître leur fonctionnement, permet de lever tout obstacle susceptible de freiner l’indexation de votre site web. La soumission manuelle La manière la plus conventionnelle pour signaler votre site web à un moteur de recherche est la soumission manuelle . Il n’y a plus qu’à remplir les formulaires en y indiquant l’adresse des pages de votre site web.
Dois-je soumettre toutes les pages de mon site web ? Vous pouvez ne soumettre que votre page d’accueil. Vous pouvez aussi soumettre toutes les pages de votre site web. Protéger vos fichiers des crawlers. Avril 2016 Présentation du fichier robots.txt Le fichier robots.txt est un fichier texte utilisé pour le référencement naturel des sites web, contenant des commandes à destination des robots d'indexation des moteurs de recherche afin de leur préciser les pages qui peuvent ou ne peuvent pas être indexées.
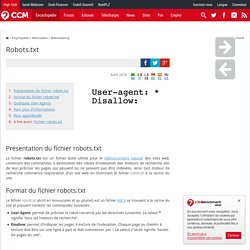
Ainsi tout moteur de recherche commence l'exploration d'un site web en cherchant le fichier robots.txt à la racine du site. Format du fichier robots.txt Le fichier robots.txt (écrit en minuscules et au pluriel) est un fichier ASCII se trouvant à la racine du site et pouvant contenir les commandes suivantes : User-Agent: permet de préciser le robot concerné par les directives suivantes. Voici des exemples de fichier robots.txt : Exclusion de toutes les pages : User-Agent: * Disallow: / Exclusion d'aucune page (équivalent à l'absence de fichier robots.txt, toutes les pages sont visitées) : User-Agent: * Disallow: Autorisation d'un seul robot : Exclusion d'un robot : Exclusion d'une page : Ligatus.
Google en une infographie. Lorsqu’on voit l’importance qu’a aujourd’hui Google dans nos tâches quotidiennes (recherches, mails…), il est difficile de s’imaginer que l’entreprise n’existait pas il y a 15 ans.
En une infographie animée, vous allez pouvoir (re)découvrir l’histoire de Google, et les avancées technologiques depuis 1995. Cette année-là, Larry Page a 22 ans, et envisage d’effectuer un doctorat en informatique à l’Université de Stanford où il rencontre Sergey Brin. A l’époque, les internautes n’étaient que 16 millions dans le monde ! L’année suivante, ils lancent BackRub : un robot d’indexation qui classe les pages suivant les liens qui les relient.
Mais en 1997, le projet devient trop puissant pour les serveurs de Stanford, et est rebaptisé Google par ses deux fondateurs. Sun Microsystems investit 100 000 dollars en 1998, Sequoia Capital et Kleiner Perkins pas moins de 25 millions l’année suivante. Source : choblab.