
Projet Big Data. Projet Option - Thales. TMSCH / TwitterCrawler. Cassandra vs MongoDB vs CouchDB vs Redis vs Riak vs HBase comparison. (Yes it's a long title, since people kept asking me to write about this and that too :) I do when it has a point.)

While SQL databases are insanely useful tools, their monopoly in the last decades is coming to an end. And it's just time: I can't even count the things that were forced into relational databases, but never really fitted them. (That being said, relational databases will always be the best for the stuff that has relations.) But, the differences between NoSQL databases are much bigger than ever was between one SQL database and another. This means that it is a bigger responsibility on software architects to choose the appropriate one for a project right at the beginning. In this light, here is a comparison of Open Source NOSQL databases Cassandra, Mongodb, CouchDB, Redis, Riak, RethinkDB, Couchbase (ex-Membase), Hypertable, ElasticSearch, Accumulo, VoltDB, Kyoto Tycoon, Scalaris, OrientDB, Aerospike, Neo4j and HBase: The most popular ones Redis (V3.2) Cassandra (2.0) Survey distributed databases - Toad for Cloud Wiki.
Overview Top This document, researched and authored by Quest's chief software architect Randy Guck, provides a summary of distributed databases. These are commercial products, open source projects, and research technologies that support massive data storage (petabyte+) using an architecture that distributes storage and processing across multiple servers. These can be considered “Internet age” databases that are being used by Amazon, Facebook, Google and the like to address performance and scalability requirements that cannot be met by traditional relational databases.
Due to their contrast in priorities and architecture compared to relational databases, these technologies are loosely referred to as “NoSQL” databases, though an absence of SQL is not a requirement. Distributed Database Concepts This section describes concepts that constitute the nature of modern distributed databases. Projet Option - Thales. Veille Techno. DataStax – Software, support, and training for Apache Cassandra. Welcome to Apache™ Hadoop®!
Welcome to Apache Pig! The Hadoop Distributed File System. The Hadoop Distributed File System (HDFS) is designed to store very large data sets reliably, and to stream those data sets at high bandwidth to user applications.

In a large cluster, thousands of servers both host directly attached storage and execute user application tasks. By distributing storage and computation across many servers, the resource can grow with demand while remaining economical at every size. We describe the architecture of HDFS and report on experience using HDFS to manage 40 petabytes of enterprise data at Yahoo! 8.1. Introduction Hadoop provides a distributed filesystem and a framework for the analysis and transformation of very large data sets using the MapReduce [DG04] paradigm. An important characteristic of Hadoop is the partitioning of data and computation across many (thousands) of hosts, and the execution of application computations in parallel close to their data. HDFS stores filesystem metadata and application data separately. 8.2. 8.2.1. 8.2.2. Apache Hadoop. Apache Hadoop is an open-source software framework for storage and large-scale processing of data-sets on clusters of commodity hardware.
Hadoop is an Apache top-level project being built and used by a global community of contributors and users.[2] It is licensed under the Apache License 2.0. The Apache Hadoop framework is composed of the following modules: Hadoop Common – contains libraries and utilities needed by other Hadoop modulesHadoop Distributed File System (HDFS) – a distributed file-system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster.Hadoop YARN – a resource-management platform responsible for managing compute resources in clusters and using them for scheduling of users' applications.Hadoop MapReduce – a programming model for large scale data processing. Apache Hadoop is a registered trademark of the Apache Software Foundation. History[edit] Hadoop was created by Doug Cutting and Mike Cafarella[5] in 2005. Architecture[edit] Gnip Provides Social Media Data for the Enterprise.
Rate Limiting. Per User or Per Application Rate limiting in version 1.1 of the API is primarily considered on a per-user basis — or more accurately described, per access token in your control.
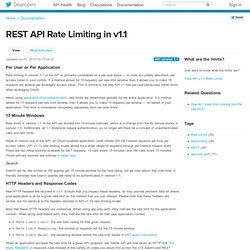
If a method allows for 15 requests per rate limit window, then it allows you to make 15 requests per window per leveraged access token. This is similar to the way API v1 had per-user/per-access token limits when leveraging OAuth. When using application-only authentication, rate limits are determined globally for the entire application. If a method allows for 15 requests per rate limit window, then it allows you to make 15 requests per window — on behalf of your application. 15 Minute Windows Rate limits in version 1.1 of the API are divided into 15 minute intervals, which is a change from the 60 minute blocks in version 1.0. Search Search will be rate limited at 180 queries per 15 minute window for the time being, but we may adjust that over time. Premium Twitter Data from Gnip. URL Expansion Gnip expands short URLs (such as links from t.co, bit.ly, and many others) and provides the extended URLs as added metadata to your streams.

Standard Language Detection. Tweets2011 Twitter Collection. Gephi, an open source graph visualization and manipulation software. Data Visualization Software. Humanitarian OpenStreetMap Team. L'Open Data au service de l'humanitaire grâce à OpenStreetMap. C’est un billet très HOT que nous vous proposons aujourd’hui.

Mais HOT pour Humanitarian OpenStreetMap Team. Le projet de cartographie libre OpenStreetMap vous connaissez déjà je suppose ? (sinon vous pouvez parcourir ce billet ou notre tag du même nom). Mais peut-être ignoriez-vous son projet spécifique dédié à l’humanitaire en cas d’urgence ? C’est l’objet de cette interview traduction. C’est pas pour dire, mais, un jour, tous ces projets positifs (et souvent d’inspiration libriste) vont finir par faire sens et nous sortir du marasme actuel… Remarque : En fin d’article nous vous proposons de revoir un passage télé évoquant le projet et l’utilité d’OpenStreetMap en pleine crise d’Haïti.
Données publiques / Open Data. CARTOGRAPHIE 2.0. OpenStreetMap dans le Dessous Des Cartes - ReLucBlog. Crowdsourcing. Crowdsourcing is a sourcing model in which individuals or organizations obtain goods and services.
These services include ideas and finances, from a large, relatively open and often rapidly-evolving group of internet users; it divides work between participants to achieve a cumulative result. The word crowdsourcing itself is a portmanteau of crowd and outsourcing, and was coined in 2005.[1][2][3][4] As a mode of sourcing, crowdsourcing existed prior to the digital age (i.e. Open data. An introductory overview of Linked Open Data in the context of cultural institutions.
Clear labeling of the licensing terms is a key component of Open data, and icons like the one pictured here are being used for that purpose. Overview[edit] The concept of open data is not new; but a formalized definition is relatively new—the primary such formalization being that in the Open Definition which can be summarized in the statement that "A piece of data is open if anyone is free to use, reuse, and redistribute it — subject only, at most, to the requirement to attribute and/or share-alike.