
Website Webmaster Search Engine Tools. Using this tool you can: - See how search engine robots analyze your or your competitors web site - Receive tips on how to improve your Meta Tags - Check the keywords used on the page and find the keyword density - Check web server operating system where site is hosted - Check website load time - Check website file size - Check URLs and links found on the page Type your URL below: Example: or URL (optional) User Agent * (optional) Sign up for FREE newsletters and mailing lists for the latest news and offerings: Submit Express Newsletter.
Search engine news and promotion tips and tricks. Please enter the letters above into the box below * This can be the Search Engine spiders User Agent and override the Spider Robot from the select box. DISCLAIMER: Please note that this tool is not a 100% accurate representation of search engine algorithms and should not be used as your sole tool for Search Engine Optimization. Gdata-python-client - Project Hosting on Google Code. Charming Python: Get started with the Natural Language Toolkit. Your humble writer knows a little bit about a lot of things, but despite writing a fair amount about text processing (a book, for example), linguistic processing is a relatively novel area for me.
Forgive me if I stumble through my explanations of the quite remarkable Natural Language Toolkit (NLTK), a wonderful tool for teaching, and working in, computational linguistics using Python. Computational linguistics, moreover, is closely related to the fields of artificial intelligence, language/speech recognition, translation, and grammar checking.
What NLTK includes It is natural to think of NLTK as a stacked series of layers that build on each other. Readers familiar with lexing and parsing of artificial languages (like, say, Python) will not have too much of a leap to understand the similar -- but deeper -- layers involved in natural language modeling. Back to top Tokenization Let's look briefly at creating a token and breaking it into subtokens: Listing 1. Probability Listing 2. Listing 3. Specify your canonical. Carpe diem on any duplicate content worries: we now support a format that allows you to publicly specify your preferred version of a URL.
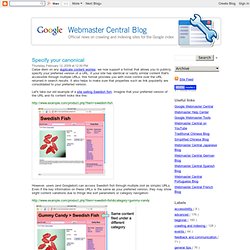
If your site has identical or vastly similar content that's accessible through multiple URLs, this format provides you with more control over the URL returned in search results. It also helps to make sure that properties such as link popularity are consolidated to your preferred version. Let's take our old example of a site selling Swedish fish.
Imagine that your preferred version of the URL and its content looks like this: However, users (and Googlebot) can access Swedish fish through multiple (not as simple) URLs. Or they have completely identical content, but with different URLs due to things such as a tracking parameters or a session ID: Now, you can simply add this <link> tag to specify your preferred version: inside the <head> section of the duplicate content URLs: SEO - Search Engine Optimization. Free SEO Tool - SEOrush. Spam Blogs Republish Your RSS Feeds? Use this to your Advantage. It is not uncommon to find websites that republish RSS feeds of other blogs without permission.
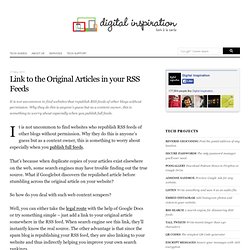
Why they do this is anyone’s guess but as a content owner, this is something to worry about especially when you publish full feeds. It is not uncommon to find websites who republish RSS feeds of other blogs without permission. Why they do this is anyone’s guess but as a content owner, this is something to worry about especially when you publish full feeds. That’s because when duplicate copies of your articles exist elsewhere on the web, some search engines may have trouble finding out the true source. What if Googlebot discovers the repulished article before stumbling across the original article on your website? So how do you deal with such web content scrapers? Well, you can either take the legal route with the help of Google Docs or try something simple – just add a link to your original article somewhere in the RSS feed.
<hr /><a href=" Blog Name</a>