
Clustering Engine. Carrot2 Search Results Clustering Engine Carrot2 organizes your search results into topics.
With an instant overview of what's available, you will quickly find what you're looking for. Choose where to search: Type your query: Teamware/teamware-detail. Semantic Annotation (SA) is about attaching meaningful structures to resources like documents or video streams in such a way that they can be used by computers to enhance the usefulness of those resources.

SA is not new: when a BBC archivist, for example, attaches thesaurus categories to programme segments for indexing they have performed semantic annotation. SA technology has changed, however, in two main ways: the invention of Information Extraction in the 1990s has made automatic SA more possiblerecent research around the Semantic Web has shown how SA can be used for scaleable conceptual search and navigation products in specific domains These developments are now leading to a new breed of consumer services that rely on SA extracted from the web by automatic means. Teamware/index. Teamware is a web-based management platform for collaborative annotation & curation.

It is a cost-effective environment for annotation and curation projects, enabling you to harness a broadly distributed workforce and monitor progress & results remotely in real time. It’s also very easy to use. A new project can be up and running in less than five minutes. (As far as we know, there is nothing else like it in this field.) GATE Teamware delivers a multi-function user interface over the Internet for viewing, adding and editing text annotations. Index. Download/index. On this page you can find the latest stable release of GATE Developer and Embedded, as well as the latest nightly built snapshots.

For other GATE products please go to GATECloud.net or follow the links to the source code from our Sourceforge pages. NOTE: if you are upgrading from one version of GATE to another you must delete your user configuration file before running the new version. The user configuration file is typically ~/.gate.xml on Unix-style platforms (including Mac OS X), C:\Documents and Settings\username\gate.xml on Windows XP, and C:\Users\username\gate.xml on Windows Vista or later. Release 7.1 (November 30th 2012) Family/process. The GATE Process describes the steps you need to take if you want to create predictable and sustainable language processing capabilities in your organisation.

The process is supported by software (most notably GATE Teamware), but it is not primarily based on tools. The process encapsulates expert knowledge and the use of that knowledge to build, educate and direct multi-role teams whose work involves the complex workflows (or business processes) necessary to do text analysis (etc.) in a cost-effective, sustainable and accurate manner. The process covers four areas: Documentation. UIMA. UIMA is a component software architecture for the development, discovery, composition, and deployment of multi-modal analytics for the analysis of unstructured information and its integration with search technologies developed by IBM.
The source code for a reference implementation of this framework has been made available on SourceForge, and later on the website of the Apache Software Foundation. Another use of UIMA is in systems that are used in medical contexts to analyze clinical notes, such as the Clinical Text Analysis and Knowledge Extraction System (CTAKES). Structure of UIMA[edit] The UIMA architecture can be thought of in four dimensions: IBM Watson - The Jeopardy Challenge[edit] In February 2011 a computer from IBM Research named Watson won a competition on Jeopardy! See also[edit] Download UIMA Framework software for free. UIMA Java Framework. UIMA. Prof. Dr. Iryna Gurevych. Current Projects. Software.
Data mining. Data mining is the process of discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems.[1] Data mining is an interdisciplinary subfield of computer science and statistics with an overall goal to extract information (with intelligent methods) from a data set and transform the information into a comprehensible structure for further use.[1][2][3][4] Data mining is the analysis step of the "knowledge discovery in databases" process or KDD.[5] Aside from the raw analysis step, it also involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, and online updating.[1] Etymology[edit] In the 1960s, statisticians and economists used terms like data fishing or data dredging to refer to what they considered the bad practice of analyzing data without an a-priori hypothesis.
List of natural language processing toolkits. Languageware. LanguageWare is a natural language processing (NLP) technology developed by IBM, which allows applications to process natural language text.
It comprises a set of Java libraries which provide a range of NLP functions: language identification, text segmentation/tokenization, normalization, entity and relationship extraction, and semantic analysis and disambiguation. The analysis engine uses Finite State Machine approach at multiple levels, which aids its performance characteristics, while maintaining a reasonably small footprint. The behaviour of the system is driven by a set of configurable lexico-semantic resources which describe the characteristics and domain of the processed language.
A default set of resources comes as part of LanguageWare and these describe the native language characteristics, such as morphology, and the basic vocabulary for the language. Open Health Natural Language Processing (OHNLP) Consortium - Vocab_Wiki. OpenNLP - Welcome to Apache OpenNLP. General Architecture for Text Engineering. GATE community and research has been involved in several European research projects including TAO, SEKT, NeOn, Media-Campaign, Musing, Service-Finder, LIRICS and KnowledgeWeb, as well as many other projects.
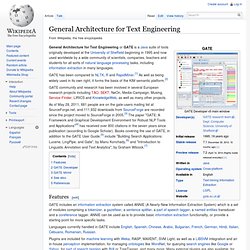
As of May 28, 2011, 881 people are on the gate-users mailing list at SourceForge.net, and 111,932 downloads from SourceForge are recorded since the project moved to SourceForge in 2005.[3] The paper "GATE: A Framework and Graphical Development Environment for Robust NLP Tools and Applications"[4] has received over 800 citations in the seven years since publication (according to Google Scholar). NLP Toolsuite. UIMA Collection Reader. Carrot2. Carrot²[1] is an open source search results clustering engine.[2] It can automatically cluster small collections of documents, e.g. search results or document abstracts, into thematic categories.
Apart from two specialized search results clustering algorithms, Carrot² offers ready-to-use components for fetching search results from various sources. OASIS Unstructured Information Management Architecture (UIMA.