
Beyond Hadoop: Next-Generation Big Data Architectures — Cloud Computing News. How to Include Third-Party Libraries in Your Map-Reduce Job. “My library is in the classpath but I still get a Class Not Found exception in a MapReduce job” – If you have this problem this blog is for you.

Java requires third-party and user-defined classes to be on the command line’s “-classpath” option when the JVM is launched. The `hadoop` wrapper shell script does exactly this for you by building the classpath from the core libraries located in /usr/lib/hadoop-0.20/ and /usr/lib/hadoop-0.20/lib/ directories. However, with MapReduce you job’s task attempts are executed on remote nodes. How do you tell a remote machine to include third-party and user-defined classes? MapReduce jobs are executed in separate JVMs on TaskTrackers and sometimes you need to use third-party libraries in the map/reduce task attempts. There are better ways of doing the same by either putting your jar in distributed cache or installing the whole JAR on the Hadoop nodes and telling TaskTrackers about their location. 1.
MinHash. In computer science, MinHash (or the min-wise independent permutations locality sensitive hashing scheme) is a technique for quickly estimating how similar two sets are.
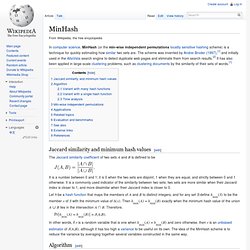
The scheme was invented by Andrei Broder (1997),[1] and initially used in the AltaVista search engine to detect duplicate web pages and eliminate them from search results.[2] It has also been applied in large-scale clustering problems, such as clustering documents by the similarity of their sets of words.[1] Jaccard similarity and minimum hash values[edit] The Jaccard similarity coefficient of two sets A and B is defined to be.
Wfc0398-liPS.pdf (application/pdf Object) TokenNGramTokenizerFactory (LingPipe API) Java.lang.Object com.aliasi.tokenizer.TokenNGramTokenizerFactory All Implemented Interfaces: TokenizerFactory, Serializable public class TokenNGramTokenizerFactoryextends Objectimplements TokenizerFactory, Serializable A TokenNGramTokenizerFactory wraps a base tokenizer to produce token n-gram tokens of a specified size.

For example, suppose we have a regex tokenizer factory that generates tokens based on contiguous letter characters. TokenizerFactory tf = new RegExTokenizerFactory("\\S+"); TokenizerFactory ntf = new TokenNGramTokenizerFactory(2,3,tf); The sequences of tokens produced by tf for some inputs are as follows. The start and end positions are calculated based on the positions for the base tokens provided by the base tokenizer. Thread Safety. Scaling Jaccard Distance for Document Deduplication: Shingling, MinHash and Locality-Sensitive Hashing « LingPipe Blog. Following on from Breck’s straightforward LingPipe-based application of Jaccard distance over sets (defined as size of their intersection divided by size of their union) in his last post on deduplication, I’d like to point out a really nice textbook presentation of how to scale the process of finding similar document using Jaccard distance.

The Book Check out Chapter 3, Finding Similar Items, from: Rajaraman, Anand and Jeff Ullman. 2010 (Draft). GettingStartedWithHadoop. Note: for the 1.0.x series of Hadoop the following articles will probably be easiest to follow: The below instructions are primarily for the 0.2x series of Hadoop.
Hadoop can be downloaded from one of the Apache download mirrors. You may also download a nightly build or check out the code from subversion and build it with Ant. Hadoop Tutorial. Introduction HDFS, the Hadoop Distributed File System, is a distributed file system designed to hold very large amounts of data (terabytes or even petabytes), and provide high-throughput access to this information.
Files are stored in a redundant fashion across multiple machines to ensure their durability to failure and high availability to very parallel applications. This module introduces the design of this distributed file system and instructions on how to operate it. Goals for this Module: Understand the basic design of HDFS and how it relates to basic distributed file system concepts Learn how to set up and use HDFS from the command line Learn how to use HDFS in your applications.
How to read all files in a directory in HDFS using Hadoop filesystem API - Hadoop and Hive. Ssh: connect to host localhost port 22: Connection refused. Install Hadoop and Hive on Ubuntu Lucid Lynx. If you've got a need to do some map reduce work and decide to go with Hadoop and Hive, here's a brief tutorial on how to get it installed.
This is geared more towards local development work than a standalone server so be careful to use best practices if you decide to deploy this live. This tutorial assumes you're running Ubuntu Lucid Lynx but it could work for other Debian based distros as well. Read on to get started! Step 1: Enable multiverse repo and get packages The first thing we need to do is make sure we've got multiverse repos installed. Www.usenix.org/publications/login/2010-02/openpdfs/leidner.pdf. Overview (Hadoop 0.20.205.0 API) Sort reducer input values in hadoop. Org.apache.mahout.clustering.minhash Class and Subpackage. Using Hadoop’s DistributedCache - Nube Technologies. Map Reduce Secondary Sort Does It All. I came across a question in Stack Overflow recently related to calculating a web chat room statistics using Hadoop Map Reduce.
The answer to the question was begging for a solution based map reduce secondary sort. I will provide details, along with code snippet, to complement my answer to the question. The Problem The data consists of a time stamp, chat room zone and number of users. The data is logged once per minute. Data Consolidation Resources.
MapReduce Applications. Apache Mahout: Scalable machine learning and data mining. The Hadoop Tutorial Series « Java. Internet. Algorithms. Ideas. A progressive set of tutorials written along the way around the Hadoop Apache Project: Issue #1: Setting Up Your MapReduce Learning Playground.
Graph partitioning in MapReduce with Cascading - Ware Dingen. 29 January 2012 I have recently had the joy of doing MapReduce based graph partitioning.

Here's a post about how I did that. Atbrox. Hadoop input format for swallowing entire files. How to Benchmark a Hadoop Cluster. Is the cluster set up correctly?
The best way to answer this question is empirically: run some jobs and confirm that you get the expected results. Benchmarks make good tests, as you also get numbers that you can compare with other clusters as a sanity check on whether your new cluster is performing roughly as expected. And you can tune a cluster using benchmark results to squeeze the best performance out of it. This is often done with monitoring systems in place, so you can see how resources are being used across the cluster. SetNumReduceTasks(1) Top K is slightly more complicated (in comparison) to implement efficiently : you might want to look at other projects like pig to see how they do it (to compare and look at ideas).
Just to get an understanding - your mappers generate <key, value>, and you want to pick top K based on value in reducer side ? Or can you have multiple key's coming in from various mappers and you need to aggregate it at reducer ? If former (that is key is unique), then a combiner to emit's top K per mapper, and then a single reducer which sorts and picks from the M * C * K tuples should do the trick (M == number of mappers, C == avg number of combiner invocations per mapper, K == number of output tuples required). Datawrangling/trendingtopics - GitHub. CS 61A Lecture 34: Mapreduce I.