
Practical Applications of Locality Sensitive Hashing for Unstructured Data. Introduction The purpose of this article is to demonstrate how the practical Data Scientist can implement a Locality Sensitive Hashing system from start to finish in order to drastically reduce the search time typically required in high dimensional spaces when finding similar items.
Locality Sensitive Hashing accomplishes this efficiency by exponentially reducing the amount of data required for storage when collecting features for comparison between similar item sets. In other words, Locality Sensitive Hashing successfully reduces a high dimensional feature space while still retaining a random permutation of relevant features which research has shown can be used between data sets to determine an accurate approximation of Jaccard similarity [2,3]. This article attempts to explain the concept of Locality Sensitive Hashing in simplistic and practical terms: A Very Brief Academic History The Locality Sensitive Hashing Use Case Introduction to Minhashing Wait a minute...?
Conclusion Resources. Data - Philipps-Universität Marburg - Datenbionik (AG Ultsch) The Fundamental Clustering Problems Suite (FCPS) offers a variety of clustering problems any algorithm shall be able to handle when facing real world data.
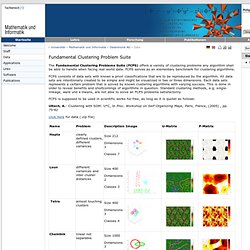
FCPS serves as an elementary benchmark for clustering algorithms. FCPS consists of data sets with known a priori classifications that are to be reproduced by the algorithm. All data sets are intentionally created to be simple and might be visualized in two or three dimensions. Each data sets represents a certain problem that is solved by known clustering algorithms with varying success. This is done in order to reveal benefits and shortcomings of algorithms in question. FCPS is supposed to be used in scientific works for free, as long as it is quotet as follows: Pvclust: An R package for hierarchical clustering with p-values. An R package for hierarchical clustering with p-values Ryota Suzuki(a, b) and Hidetoshi Shimodaira(a) a) Department of Mathematical and Computing Sciences Tokyo Institute of Technology b) Ef-prime, Inc.

What is pvclust? Pvclust is an R package for assessing the uncertainty in hierarchical cluster analysis. Pvclust provides two types of p-values: AU (Approximately Unbiased) p-value and BP (Bootstrap Probability) value. Pvclust performs hierarchical cluster analysis via function hclust and automatically computes p-values for all clusters contained in the clustering of original data. An example of analysis on Boston data (in library MASS) is shown in the right figure. 14 attributes of houses are examined and hierarchical clustering has been done. Installation pvclust can be easily installed from CRAN. Install.packages("pvclust") On Windows you can use Packages -> Install package(s) from CRAN... from menu bar.
Download The latest version should be found at the CRAN web site [FAQ] Q. Www.stat.sc.edu/~hitchcock/compare_hier_fda.pdf. Tools - InfoVis2. Finding similar items using minhashing. You find yourself with a sufficiently large pile of items (tweets, blog posts, cat pictures) and a key-value database.
New items are arriving every minute and you’d really like a way of finding similar items that already exist in your dataset (either for duplication detection or finding related items). Clearly we don’t want to scan our entire existing database of items every time we receive a new item but how do we avoid doing so? Minhashing to the rescue! Minhashing Minhashing is a technique for generating signatures for items. Similarity For this we use the Jaccard Similarity: That is, the Jaccard Similarity is the number of elements two sets have in common divided by the total number elements in both sets.
If we treat our items as sets and the item attributes (such as tags or keywords) as the set elements then we can use the above definition to compute the similarity between two items. A quick example. . Multidimensional scaling. Types[edit] Classical multidimensional scaling Also known as Principal Coordinates Analysis, Torgerson Scaling or Torgerson–Gower scaling. Takes an input matrix giving dissimilarities between pairs of items and outputs a coordinate matrix whose configuration minimizes a loss function called strain.[1] Metric multidimensional scaling A superset of classical MDS that generalizes the optimization procedure to a variety of loss functions and input matrices of known distances with weights and so on.
Non-metric multidimensional scaling In contrast to metric MDS, non-metric MDS finds both a non-parametric monotonic relationship between the dissimilarities in the item-item matrix and the Euclidean distances between items, and the location of each item in the low-dimensional space. Comparing Clusterings. BibTeX @MISC{Meila02comparingclusterings, author = {Marina Meila}, title = {Comparing Clusterings}, year = {2002}} Years of Citing Articles Bookmark OpenURL Abstract This paper proposes an information theoretic criterion for comparing two clusterings of the same data set.
Citations.