
Levée de fonds : les pires flops de startups. Building a system for machine and event-oriented data - Data Day Seat… SQL ID Specific Performance Information. When you need to have information about one SQL_ID and don’t need everything and the kitchen sink, there are a few different ways to collect this via Oracle.
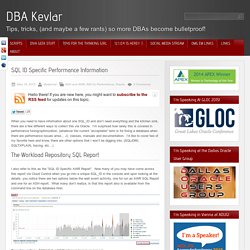
I’m surprised how rarely this is covered in performance tuning/optimization, (whatever the current “acceptable” term is for fixing a database when there are performance issues arise… J) classes, manuals and documentation. I’d like to cover two of my favorite here and know, there are other options that I won’t be digging into, (SQLd360, SQLTXPLAIN, tracing, etc…) I also refer to this as the “SQL ID Specific AWR Report”. Now many of you may have come across this report via Cloud Control when you go into a unique SQL_ID in the console and upon looking at the details, you notice there are two options below the wait event actrivity, one for run an AWR SQL Report and one for an ASH report.
BrightAct Packs - Starter Pack. Investors Throw Datadog A $31M Bone. Datadog, a cloud service that helps customers monitor infrastructure and software, whether all in the cloud or a hybrid on-premises-cloud environment, announced $31M in Series C funding today.
The round was led by Index Ventures with help from RTP Ventures, OpenView Venture Partners and what they referred to as “other equity holders.” Index and OpenView helped fund the Series B round last February, and RTP has been involved since seed funding in April, 2011. The $31M brings the total raised to $53.4M. Datadog, which launched in 2011 and produced its first product in 2013, provides a dashboard of data about any cloud services that can plug into the system. It can work with several popular services such as Amazon Web Services, Microsoft Azure and Google Compute Engine. Rocana. ScalingData Emerges With $4.4M to Build Hadoop ‘Killer App’ - Venture Capital Dispatch.
Should you start a tech company? April 24, 2015 I occasionally get very hands-on in accelerating a raw start-up.
Typically this is when an engineer comes to me with an unquestionably clever idea and asks me — sometimes in very broken English — whether and how he can get rich from it. So let’s collect some thoughts on the subject. This post can be construed as fitting into my “not-very-organized series” about the keys to success. The product plan A start-up product idea needs to satisfy multiple criteria. It should be obviously appealing to sufficiently many customers, and be worth sufficiently much money to them.It should be something the startup can do with very few resources …… but which much larger potential competitors cannot. That usually means that the idea: Should be based on an architecture that is anti-strategic to incumbent players …… but which fits customers’ technology strategies just fine. Criticisms I’ve made repeatedly of specific ideas include: Getting to a good plan Gathering resources But please stay tuned.
Optimizing the Modern Data Warehouse - with Hortonworks, Attunity and RCG. Ingest Tips / What was Hot at Strata 2015? - Ingest Tips. Here’s a pro-tip (although not necessarily an ingest tip): You go to conferences to get industry gossip, and you get the best gossip at the exhibit hall.

Best time is Thursday evening when beer and cocktails are served. People relax, have fun and even competitors seem to spill the beans on not-yet-announced products and features. But for me, the really interesting information comes from our customers – what are they interested in? Where are the current pain points? Which product is the current trendy “cure for cancer”? I learn all those mostly from the questions people ask me. So, what is everyone interested in? Metadata - For me, this was definitely the biggest surprise of the conference. If you attended my presentations and want the slides, you can find them here: Hope you got to attend Strata and learned something new. The 10 Coolest Big Data Startups Of 2014 - Page: 7.
Featured On Printer Week 2015.
A first look at Spark. By Joseph Rickert Apache Spark, the open-source, cluster computing framework originally developed in the AMPLab at UC Berkeley and now championed by Databricks is rapidly moving from the bleeding edge of data science to the mainstream.
Interest in Spark, demand for training and overall hype is on a trajectory to match the frenzy surrounding Hadoop in recent years. Next month's Strata + Hadoop World conference, for example, will offer three serious Spark training sessions: Apache Spark Advanced Training, SparkCamp and Spark developer certification with additional spark related talks on the schedule. It is only a matter of time before Spark becomes a big deal in the R world as well. If you don't know much about Spark but want to learn more, a good place to start is the video of Reza Zadeh's keynote talk at the ACM Data Science Camp held last October at eBay in San Jose that has been recently posted. An introduction to containers, Kubernetes, and the trajectory of modern cloud computing.
In the coming weeks we will be publishing a series of blog posts to lay out our view on container technology and share some of the knowledge gained from running Google’s services on containers for over ten years.
As a team of Google product managers, engineers, operators, and architects, our goal is to help you understand how the “container revolution” will help you build and run more efficient and effective applications. We’ve invited Google Cloud Platform’s Global Head of Solutions, Miles Ward, to kick this off! Hello everyone, and welcome to our new blog series covering one of the most important areas of innovation for modern computing: containerization. How ScalingData Uses Kafka for Event-Oriented Machine Data - Eric Sammer.