
Foreign key. The table containing the foreign key is called the referencing or child table, and the table containing the candidate key is called the referenced or parent table.[4] For example, consider a database with two tables: a CUSTOMER table that includes all customer data and an ORDER table that includes all customer orders.
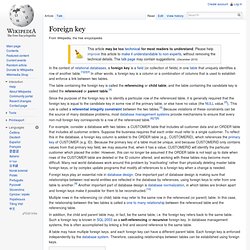
Suppose the business requires that each order must refer to a single customer. To reflect this in the database, a foreign key column is added to the ORDER table (e.g., CUSTOMERID), which references the primary key of CUSTOMER (e.g. ID). Because the primary key of a table must be unique, and because CUSTOMERID only contains values from that primary key field, we may assume that, when it has a value, CUSTOMERID will identify the particular customer which placed the order.
Foreign keys play an essential role in database design. In addition, the child and parent table may, in fact, be the same table, i.e. the foreign key refers back to the same table. Referential actions[edit] Unique key. A unique key or primary key is a key that uniquely defines the characteristics of each row.

The primary key has to consist of characteristics that cannot collectively be duplicated by any other row. In an entity relationship diagram of a data model, one or more unique keys may be declared for each data entity. Each unique key is composed from one or more data attributes of that data entity. The set of unique keys declared for a data entity is often referred to as the candidate keys for that data entity. From the set of candidate keys, a single unique key is selected and declared the primary key for that data entity.
The primary key may consist of a single attribute or a multiple attributes in combination. Author TABLE Schema: AuthorTable(AUTHOR_ID,AuthorName,CountryBorn,YearBorn) Book TABLE Schema: Book(ISBN,Author_ID,Title,Publisher,Price) Here we can see that AUTHOR_ID serves as the Primary Key in AuthorTable but also serves as the Foreign Key on the BookTable. Join (SQL) A programmer writes a JOIN statement to identify the records for joining.
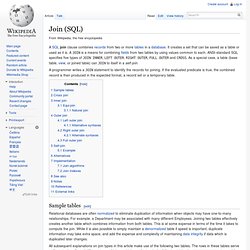
If the evaluated predicate is true, the combined record is then produced in the expected format, a record set or a temporary table. Relational databases are often normalized to eliminate duplication of information when objects may have one-to-many relationships. For example, a Department may be associated with many different Employees. Joining two tables effectively creates another table which combines information from both tables.
This is at some expense in terms of the time it takes to compute the join. Note: In the Employee table above, the employee "John" has not been assigned to any department yet. This is the SQL to create the aforementioned tables. CROSS JOIN returns the Cartesian product of rows from tables in the join. Example of an explicit cross join: SELECT *FROM employee CROSS JOIN department; Example of an implicit cross join: SELECT *FROM employee, department; We can write equi-join as below,