
Tensor2. Algorithm - What is the most efficient way to match the IP addresses to huge route entries? Trie. A trie for keys "A","to", "tea", "ted", "ten", "i", "in", and "inn".
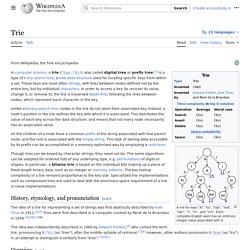
Note that this example does not have all the children alphabetically sorted from left to right as it should be (the root and node 't'). In the example shown, keys are listed in the nodes and values below them. Each complete English word has an arbitrary integer value associated with it. A trie can be seen as a tree-shaped deterministic finite automaton. Each finite language is generated by a trie automaton, and each trie can be compressed into a deterministic acyclic finite state automaton. Though tries are usually keyed by character strings,[not verified in body] they need not be. History and etymology[edit] Applications[edit]
Scalable Tree-Based Architectures for IPv4/v6 Lookup Using Prefix Partitioning. Memory efficiency and dynamically updateable data structures for Internet Protocol (IP) lookup have regained much interest in the research community.
In this paper, we revisit the classic tree-based approach for solving the longest prefix matching (LPM) problem used in IP lookup. In particular, we target our solutions for a class of large and sparsely distributed routing tables, such as those potentially arising in the next-generation IPv6 routing protocol. Due to longer prefix lengths and much larger address space, preprocessing such routing tables for tree-based LPM can significantly increase the number of prefixes and/or memory stages required for IP lookup.
We propose a prefix partitioning algorithm (DPP) to divide a given routing table into k groups of disjoint prefixes (k is given). The algorithm employs dynamic programming to determine the optimal split lengths between the groups to minimize the total memory requirement. Hoang Le, Viktor K. DXR: Direct / Range Routing Lookups. DXR: a Billion IPv4 Routing Lookups per Second in Software Overview DXR is an IPv4 routing lookup scheme based on transforming large routing tables to compact lookup structures which easily fit into cache hierarchies of modern CPUs.

It supports various memory/speed tradeoffs, and its throughput scales almost linearly with the number of CPU cores. The most compact configuration, D16R, distills a real-world BGP snapshot with 513,644 IPv4 prefixes and 239 distinct next hops into a structure consuming only 932 Kbytes, less than 2 bytes per prefix, and exceeds 100 million lookups per second (MLps) on a single commodity CPU core in synthetic tests with uniformly random queries. Some other DXR configurations exceed 200 MLps per CPU core at the cost of increased memory footprint, and deliver aggregate throughputs exceeding one billion lookups per second with multiple parallel worker threads.
How does this work? DXR partitions the entire IPv4 address space into 2^K uniform blocks called chunks. Code. Cross compiling C projects with external dependencies: Click modular router and the Raspberry PI. Introduction At IBCN – my research group – we rely on Click router for implementing and evaluating various Internet communication protocols.

Click is a modular software router in C++ that was developed at the end of the last century by Eddie Kohler and others at MIT (the original research paper is available here). Apart from the IP routing functionality that ships with Click, we’ve added a CoAP implementation that has been widely tested at ETSI Plugtest interoperability events. We also have a working 6LoWPAN implementation that was tested in at last year’s summer IETF in Berlin. Lately, we’ve also added DTLS integration via CyaSSL. Usually we run Click directly on x86 machines (e.g. on our laptops), sometimes we run it on Alix system boards via voyage linux.
A well-known example is the Raspberry PI that packs an armv6 CPU. To wrap up the introduction: this post documents some of the problems I encountered while cross compiling Click in userlevel with shared lib dependencies for the RPI. [Click Modular Router] Protocol implementation tutorial - intro. Click Modular Router is a pretty cool “modular packet processing and analysis” framework, the only problem is the harsh learning curve.
![[Click Modular Router] Protocol implementation tutorial - intro](http://cdn.pearltrees.com/s/pic/th/protocol-implementation-119177612)
Our work group used this framework for a school project : a PoC of the LISP protocol on a virtual machine to explore the NFV concept. In spite of the difficulty to approach Click Modular Router, it has a lot of benefits and potential. This network framework aims at autonomous network equipment, thus Click Modular Router isn’t for your typical client side protocol. If you want to have a fine control over a particular network system or you want to use an exotic protocol this tutorial is for you. If you are still reading, be aware that (almost) everything you do with Click Modular Router can be deployed on a optimised xen virtual machine: clickOS. This tutorial is an attempt at sharing “what I wish I knew before starting this school project”. I’m not a native english speaker so if you notice language “problems”, quirks or typos let me know.
Elements.