
Big Data : La jungle des différentes distributions open source Hadoop. En 2004, Google a publié un article présentant son algorithme de calcul à grande échelle, MapReduce, ainsi que son système de fichier en cluster, GoogleFS.

Rapidement (2005) une version open source voyait le jour sous l’impulsion de Yahoo. Aujourd’hui il est difficile de se retrouver dans la jungle d’Hadoop pour les raisons suivantes : Ce sont des technologies jeunes.Beaucoup de buzz et de communication de sociétés qui veulent prendre le train Big Data en marche.Des raccourcis sont souvent employés (non MapReduce ou un équivalent n’est pas suffisant pour parler d’Hadoop).Beaucoup d’acteurs différents (des mastodontes, des spécialistes du web, des start-up, …).
Dans une distribution Hadoop on va retrouver les éléments suivants (ou leur équivalence) HDFS, MapReduce, ZooKeeper, HBase, Hive, HCatalog, Oozie, Pig, Sqoop, … Dans cet article on évoquera les trois distributions majeures que sont Cloudera, HortonWorks et MapR, toutes les trois se basant sur Apache Hadoop. The Glowing Python. Blueprint for a Big Data Solution. In today’s world, data is money.

Companies are scrambling to collect as much data as possible, in an attempt to find hidden patterns that can be acted upon to drive revenue. However, if those companies aren’t using that data, and they’re not analyzing it to find those hidden gems, the data is worthless. One of the most challenging tasks when getting started with Hadoop and building a big data solution is figuring out how to take the tools you have and put them together. The Hadoop ecosystem encompasses about a dozen different open-source projects. L’évolution des architectures décisionnelles avec Big Data. Nous vivons une époque formidable.

En revenant un peu sur l’histoire de l’informatique, on apprend que les capacités que cela soit de RAM, disque ou CPU sont de grands sponsors de la loi de Moore au sens commun du terme (« quelque chose » qui double tous les dix-huit mois). Ces efforts seraient vains si les prix ne suivaient pas le phénomène inverse (divisés par 200 000 en 30 ans pour le disque par exemple). Exposé comme cela, on se dit que nos envies ne peuvent connaitre de limite et qu’il suffit de changer la RAM, le disque ou le CPU pour prendre en charge l’explosion du volume de données à traiter qui globalement suit bien la loi de Moore aussi. Figure 1 Evolutions hardware, 2011, Alors où est le problème, qu’est qui fait que nos architectures décisionnelles aujourd’hui, non contentes de coûter de plus en plus chères, sont aussi en incapacité à se projeter sur des Tera ou des Peta de données.
Figure 2 Evolution du débit des disques durs, source : wikipedia Architecture In Memory. CR du petit-déjeuner organisé par OCTO et Quartet FS « L’analyse décisionnelle en temps réel Convergence entre Big Data et Complex Event Processing » Agenda : Introduction aux enjeux d’analyse de données en temps réelPrésentation des architectures d’analyse de donnéesPrésentation de la solution Open Source ESPERPrésentation de la solution ActivePivot Sentinel (Quartet FS)Questions/Réponses Définition : « Un système d’analyse de données temps réel est un système évènementiel disponible, scalable et stable capable de prendre des décisions (actions) avec une latence inférieure à 100ms » 100ms est l’ordre de grandeur retenu lorsque l’on parle de « temps réel ».

Cette valeur permet de prendre les décisions dans un temps adapté au business. Quelles différences avec l’analyse traditionnelle ? Quels intérêts pour les entreprises ? Les entreprises sont déjà aujourd’hui confrontées aux problématiques de volumétrie. Pourquoi CEP ? Le CEP apparaît être une opportunité pour l’analyse et la prise de décision en temps réel là ou même le stockage sur cache/grille de données seul peut montrer ses limites :
MapReduce Patterns. In this article I digested a number of MapReduce patterns and algorithms to give a systematic view of the different techniques that can be found on the web or scientific articles.
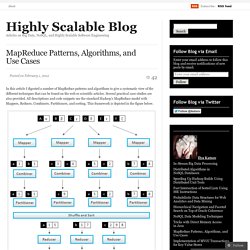
Several practical case studies are also provided. All descriptions and code snippets use the standard Hadoop’s MapReduce model with Mappers, Reduces, Combiners, Partitioners, and sorting. This framework is depicted in the figure below. MapReduce Framework Counting and Summing Problem Statement: There is a number of documents where each document is a set of terms. Solution: Let start with something really simple. The obvious disadvantage of this approach is a high amount of dummy counters emitted by the Mapper. MapReduce - La révolution dans l’analyse des BigData.