
Wordcloud « Fells Stats. An update to the wordcloud package (2.2) has been released to CRAN.
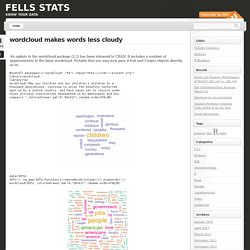
It includes a number of improvements to the basic wordcloud. Notably that you may now pass it text and Corpus objects directly. as in: #install.packages(c("wordcloud","tm"),repos=" library(wordcloud) library(tm) wordcloud("May our children and our children's children to a thousand generations, continue to enjoy the benefits conferred upon us by a united country, and have cause yet to rejoice under those glorious institutions bequeathed us by Washington and his compeers. ",colors=brewer.pal(6,"Dark2"),random.order=FALSE) Text mining and word cloud fundamentals in R : 5 simple steps you should know.
Load the text The text is loaded using Corpus() function from text mining (tm) package.
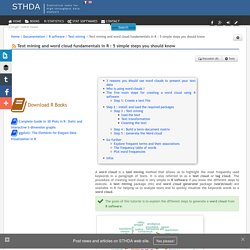
Corpus is a list of a document (in our case, we only have one document). In the example below, I loaded a .txt file hosted on STHDA website but you can use one from your computer. Wordcloud « Fells Stats. Scraping Data to build N-gram Word Clouds in R (LifeVantage Use Case) As social networks, news, blogs, and countless other sources flood our data lakes and warehouses with unstructured text data, R programmers look to tools like word clouds (aka tag clouds) to aid in consumption of the data.

Using the tm.plugin.webmining package to scrape data on the Nrf2 antioxidant supplement-maker LifeVantage, this tutorial extends several existing tutorials to go beyond 1-gram (i.e. single-word) word clouds to N-gram word clouds (i.e. 2 or more words per token). Word clouds are visualization tools wherein text data are mined such that important terms are displayed as a group according to some algorithm (e.g. scaling of words based upon term density, shading corresponding to frequency, etc.). This can allow a researcher to summarize thousands or even millions of text records in only a glance.
To get started, we load a few good libraries. The goal is to scrape an example dataset related to LifeVantage, the maker of Nrf2-activating supplement Protandim. Done! Voilà! How to make R word cloud display most frequent term in lighter shade of color. Building a Better Word Cloud. A few weeks ago I attended the NYC Data Visualization and Infographics meetup, which included a talk by Junk Charts blogger Kaiser Fung.
Given the topic of his blog, I was a bit shocked that the central theme of his talk was comparing good and bad word clouds. He even stated that the word cloud was one of the best data visualizations of the last several years. I do not think there is such a thing as a good word cloud, and after the meetup I left unconvinced; as evidenced by the above tweet.
This tweet precipitated a brief Twitter debate about the value of word clouds, but from that straw poll it seemed the Nays had the majority. My primary gripe is that space is meaningless in word clouds. Since then, I have been inundated with word clouds. First, I was struck by one of the comments at the NYVIZ meetup. This is the result of my effort to build a better word cloud… Next, I wanted to improve the word cloud, but not redefine it. For the y-axis I wanted to maximize readability. Related. ThinkToStartR package - ThinkToStart. I just started to work on my new package for this blog.
This R package will include the code of all my tutorials and will make it accessible with easy function calls. Install To install the ALPHA version of the package open up R and use: require(devtools) #install if necessary (install.packages("devtools") dev_mode(on=T) install_github("ThinkToStartR",username="JulianHill",subdir="ThinkToStartR") Usage In this first ALPHA version the package just includes some functions.
You can call the functions with the ThinkToStart function: How I used R to create a word cloud, step by step. Or: R is less scary than you thought!
R, the open source package, has become the de facto standard for statistical computing and anything seriously data-related (note I am avoiding the term ‘big data’ here – oops, too late!). Generating Twitter Wordclouds in R (Prompted by an Open Learning Blogpost) Building a Better Word Cloud. Analyze Text Similarity with R: Latent Semantic Analysis and Multidimentional Scaling. 11 Mar 2013 r semantic analysis text mining knowledge forum Background One of the most pressing questions I have been pondering upon when redesigning Knowledge Forum is how to represent the knowledge space of a community to better support idea improvement.

Many people think Knowledge Forum as another discussion forum (or learning management system) with a 2-D interface (see below). This notion lead people to treat a Knowledge Forum view merely as a container of notes. The reason why this happens is because users usually fail to recognize one important principle behind the design of Knowledge Forum view: to support multiple perspectives of community knowledge. Embarking on this challenge, I started to think maybe the first alternative perspective I could work on is semantic relations among notes in a view. In this post, I am demoing a “toy” (made with R) that presents my initial endeavor to solve this problem. Below I am describing steps of analysis of the prototypic tool. # 2. . # 3.