
The vowel space. Vowels can be tricky to describe phonetically because they are points, or rather areas, within a continuous space. Any language will have a certain finite number of contrasting vowels, each of which may be represented with a discrete alphabetic symbol; but phonetically each will correspond to a range of typical values, and between any two actual vowel sounds there is a gradient continuum. A good analogy can be made with colour.
Table.pdf. Gmail: Email from Google. Gmail: Email from Google. The co-occurrence of multisensory facilitation and cross-modal conflict in the human brain. 115.pdf. Speech Formant Synthesizer (With bonus Turkish vowels pack :P) View topic - Finding input signal frequency in ChucK. Well, there is of course this; and this; And the relevant files of example code in the examples directory. .... and when you covered those you'll have noticed that Ge and Rebecca never actually tell us how to simply take a guitar tone and get from that what note it is.

They seem to avoid the issue.. we might even start to suspect that they don't know. Voce.sourceforge.net. Fonnesbeck/ScipySuperpack @ GitHub. P2TK - Penn Phonetics Toolkit. Speech Recognition using Sphinx : Don’t Try This At Home. Patent US20050114119 - Method of and apparatus for enhancing dialog using formants - Google Patents. This application claims the priority of Korean Patent Application No. 2003-82976, filed on Nov. 21, 2003, in the Korean Intellectual Property Office, the disclosure of which is incorporated herein in its entirety by reference. 1.

Field of the Invention The present general inventive concept relates to a dialog enhancing system, and more particularly, to a dialog enhancing method and apparatus to boost formants of dialog zones without changing sound zones. 2. Description of the Related Art. Linear Prediction Coding - S4LinearPredictionCoding2009.pdf. Offline Speech Recognition With PocketSphinx. Timbral Analysis & Orchestration. Formant Analysis Most acoustic instruments produce prominent formant frequencies.

Formants are resonances that are characteristic of a sound. Phonemes can be characterized by 3 prominent formants or frequency regions. A particular set of formant frequencies characterize each vowel and are relatively independent of a voices pitch. Female and male voices obviously have different formant frequency ranges, however the ratio between formant frequencies is consistent across males, females, adults, and children. Acoustic Phonetics: Formants. Formants For the purposes of distinguishing vowels from each other, we are more interested in the frequency response curves (indicating the preferred resonating frequencies of the vocal tract) rather than in the raw spectrum of the wave.
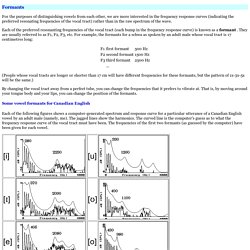
Each of the preferred resonanting frequencies of the vocal tract (each bump in the frequency response curve) is known as a formant . They are usually referred to as F1, F2, F3, etc. For example, the formants for a schwa as spoken by an adult male whose vocal tract is 17 centimetres long: (People whose vocal tracts are longer or shorter than 17 cm will have different frequencies for these formants, but the pattern of 1x-3x-5x will be the same.) Sound symbolism effects across languages: Implications for global brand names - IJRM Online.pdf. Assignment2.pdf. Dakuten. _pdf. 58_275.pdf - _pdf. PII: S0022-5371(69)80028-9 - 1-s2.0-S0022537169800289-main.pdf. NeuroImage - Pathways to seeing music: Enhanced structural connectivity in colored-music synesthesia. Abstract Synesthesia, a condition in which a stimulus in one sensory modality consistently and automatically triggers concurrent percepts in another modality, provides a window into the neural correlates of cross-modal associations.

While research on grapheme–color synesthesia has provided evidence for both hyperconnectivity-hyperbinding and disinhibited feedback as potential underlying mechanisms, less research has explored the neuroanatomical basis of other forms of synesthesia. In the current study we investigated the white matter correlates of colored-music synesthesia. As these synesthetes report seeing colors upon hearing musical sounds, we hypothesized that they might show unique patterns of connectivity between visual and auditory association areas. We used diffusion tensor imaging to trace the white matter tracts in temporal and occipital lobe regions in 10 synesthetes and 10 matched non-synesthete controls. Speech Communication - Investigating the impact of lip visibility and talking style on speechreading performance. Abstract It has long been known that visual information from a talker’s mouth and face plays an important role in the perception and understanding of spoken language.

The reported experiments explore the impact of lip visibility (Experiments 1 & 2) and speaking style (Experiment 2) on talker speechreadability. Specifically we compare speechreading performance (words in Experiment 1; sentences in Experiment 2 with low level auditory input) from talkers with natural lips, with brightly coloured lips and with concealed lips. Results reveal that highlighting the lip area by the application of lipstick or concealer improves speechreading, relative to natural lips. Furthermore, speaking in a clear (rather than conversational) manner improves speechreading performance, with no interaction between lip visibility and speaking style. Cross-modal facilitation of mental rotation: Effects of modality and complexity - Aksentijevic - 2012 - British Journal of Psychology. 115.pdf. Vocal tract length and formant frequency dispersion correlate with body size in rhesus macaques.
Linear predictive coding. Overview[edit] LPC starts with the assumption that a speech signal is produced by a buzzer at the end of a tube (voiced sounds), with occasional added hissing and popping sounds (sibilants and plosive sounds).

Although apparently crude, this model is actually a close approximation of the reality of speech production. The glottis (the space between the vocal folds) produces the buzz, which is characterized by its intensity (loudness) and frequency (pitch). The vocal tract (the throat and mouth) forms the tube, which is characterized by its resonances, which give rise to formants, or enhanced frequency bands in the sound produced. Lowrey14.vp - LowreyBookChapter2006.Final.pdf. Phonetic symbolism in English word-formation. Maurer_bouba.pdf. Synaesthesia - JCS.pdf. Crossmodal correspondences: a tutor... [Atten Percept Psychophys. 2011.