
Intro — Hector - Java Client for Cassandra. Hector is a high level Java client for Apache Cassandra currently in use on a number of production systems some of which have node counts into the hundreds.
Issues generally are fixed as quickly as possbile and releases done frequently. Apache Cassandra is a highly available column oriented database. Hector is the greatest warrior in the greek mythology, Troy’s builder and brother of Cassandra. Cassandra Migration to EC2. This is a guest post by Tommaso Barbugli the CTO of getstream.io, a web service for building scalable newsfeeds and activity streams.
In January we migrated our entire infrastructure from dedicated servers in Germany to EC2 in the US. The migration included a wide variety of components, web workers, background task workers, RabbitMQ, Postgresql, Redis, Memcached and our Cassandra cluster. Our main requirement was to execute this migration without downtime. This article covers the migration of our Cassandra cluster. [CASSANDRA-3677] NPE during HH delivery when gossip turned off on target. NSFAQ (Not So Frequently Asked Questions) [CASSANDRA-3870] Internal error processing batch_mutate: java.util.ConcurrentModificationException on CounterColumn. I don't think that is the goal of that code.
![[CASSANDRA-3870] Internal error processing batch_mutate: java.util.ConcurrentModificationException on CounterColumn](http://cdn.pearltrees.com/s/pic/th/processing-countercolumn-88243233)
We already have code for that (make sure a node don't get overwhelm writing hints locally) in sendToHintedEndpoints. Missed the totalHintsInProgress check. So I'm wondering, do we really have a strong reason for waiting for hints during writes in the first place. IMHO no, other than CL ANY. I know it's different in 1.0 but HH provides weak guarantees. I'm not saying the attached patch won't work, but it does help making the write path more complicated and 'messy' that I'd like it to be. Synchronizing Clocks In a Cassandra Cluster, Pt. 2: Solutions. This article was originally written by Viliam Holub This is the second part of a two part series.
Before you read this, you should go back and read the original article, “Synchronizing Clocks In a Cassandra Cluster Pt. 1 – The Problem.” In it, I covered how important clocks are and how bad clocks can be in virtualized systems (like Amazon EC2) today. In today’s installment, I’m going to cover some disadvantages of off-the-shelf NTP installations, and how to overcome them. Configuring NTP daemons As stated in my last post, it’s the relative drift among clocks that matters most. Configure the whole cluster as a mesh NTP uses tree-like topology, but allows you to connect a pool of peers for better synchronization on the same strand level. Synchronizing Clocks In a Cassandra Cluster, Pt. 1: The Problem. This article was originally written by Viliam Holub Cassandra is a highly-distributable NoSQL database with tunable consistency.
What makes it highly distributable makes it also, in part, vulnerable: the whole deployment must run on synchronized clocks. It’s quite surprising that, given how crucial this is, it is not covered sufficiently in literature. And, if it is, it simply refers to installation of a NTP daemon on each node which – if followed blindly – leads to really bad consequences. The History of Apache Cassandra. HBase vs Cassandra. Making Things Easier with Cassandra GUI 2.0. Cassandra GUI evolved from its first version and new version includes bug fixes and enhanced features.
New features. Complete pagination for Row view of explorerSearch rows by their names. (Filtered on the fly as you type.)Filtering non displayable data and label them with warnings. Bug Fixes Remote connection problemConnect to Remote Cassandra server without restarting the server. Start the Server You can download the server here. Cassandra-user - frequent client exceptions on 0.7.0. Cassandra Indexing: The good, the bad and the ugly. We Recommend These Resources Within NoSQL, the operations of indexing, fetching and searching for information are intimately tied to the physical storage mechanisms.
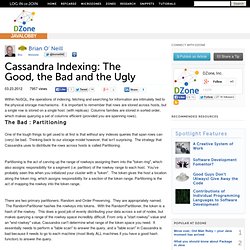
It is important to remember that rows are stored across hosts, but a single row is stored on a single host. (with replicas) Columns families are stored in sorted order, which makes querying a set of columns efficient (provided you are spanning rows). The Bad : Partitioning One of the tough things to get used to at first is that without any indexes queries that span rows can (very) be bad. Partitioning is the act of carving up the range of rowkeys assigning them into the "token ring", which also assigns responsibility for a segment (i.e. partition) of the rowkey range to each host. Cloud Architecture Tutorial - Running in the Cloud (3of3)
Announcing Astyanax. Compressed families not created on new node. Cassandra NYC 2011: Nathan Milford - Cassandra for System Admins. Cassandra for LOBS. Database storage is expensive.
This is especially true if you build a traditional SAN based M+N cluster. The cost of the storage array, fiber channel switches, fiber channel interfaces, drives the cost per terabyte into the thousands quite easily. And while storage costs in general are plummeting, SAN storage costs are falling at a slower rate, widening the gap between SAN and direct attached storage. Given the cost of SAN storage, it would be unfortunate to waste it which is what we discovered we were doing.
Our platform makes a lot of 3rd party service calls. "Building on Quicksand" Paper for CIDR (Conference on Innovative Database Research) - PatHelland's WebLog. DataStax Cassandra 1.0 Documentation. This section describes how to upgrade Cassandra 0.8.x to 1.0.x and how to upgrade between minor releases of Cassandra 1.0.x.
The procedures also apply to DataStax Community Edition. What’s new in Cassandra 1.0: Compression. Cassandra 1.0 introduces support for data compression on a per-ColumnFamily basis, one of the most-requested features since the project started. Compression maximizes the storage capacity of your Cassandra nodes by reducing the volume of data on disk. In addition to the space-saving benefits, compression also reduces disk I/O, particularly for read-dominated workloads. Compression benefits Besides data size, compression typically improves both read and write performance. Cassandra is able to quickly find the location of rows in the SSTable index, and only decompresses the relevant row chunks. Netflix Benchmarks on AWS Show Cassandra NoSQL Still Has the Goods. A little more than a year ago, Apache Cassandra's reputation was untouchable.

It was blowing other NoSQL data stores out of the water in benchmarks and in our very own DZone popularity poll. What else would you expect from the data solution that was originally designed to handle the data on Facebook. How could it not be the top solution out there? But last year, Cassandra's reputation seemed like it got a little tarnished by stories about its instability and difficult learning curve. And then there were subsequent migrations which were induced by the emerging and the growing popularity of MongoDB. The Apache Cassandra Project. Intro — Hector v0.8.x documentation. Sebgiroux/Cassandra-Cluster-Admin - GitHub. DataStax Cassandra 0.8 Documentation. Effective tuning depends not only on the types of operations your cluster performs most frequently, but also on the shape of the data itself. For example, Cassandra’s memtables have overhead for index structures on top of the actual data they store.
If the size of the values stored in the columns is small compared to the number of columns and rows themselves (sometimes called skinny rows), this overhead can be substantial. Thus, the optimal tuning for this type of data is quite different than the optimal tuning for a small numbers of columns with more data (fat rows). Tuning the Cache. Zznate/cassandra-stress - GitHub. SLF4J. NodeTool. More and more instrumentation is being added to Cassandra via standard JMX apis. The nodetool utility (nodeprobe in versions prior to 0.6) provides a simple command line interface to these exposed operations and attributes. See Operations for a more high-level view of when you would want to use the actions described here. Note: This utility currently requires the same environment as cassandra itself, namely the same classpath (including log4j.properties), and a valid storage-conf property.
Running bin/nodetool with no arguments produces some usage output. The -host argument is required, the -port argument is optional and will default to 8080 if not supplied. Ring The ring command will present node status and an ascii art rendition of the ring, as determined by the node being queried. Cassandra Write Performance – A quick look inside Application Performance. I was looking at Cassandra, one of the major NoSQL solutions, and I was immediately impressed with its write speed even on my notebook. But I also noticed that it was very volatile in its response time, so I took a deeper look at it. First Cassandra Write Test I did the first write tests on my local machine, but I had a goal in mind. MX4J - Open Source Java Management Extensions. Linux performance basics. I want to write about Cassandra performance tuning, but first I need to cover some basics: how to use vmstat, iostat, and top to understand what part of your system is the bottleneck -- not just for Cassandra but for any system. vmstat You will typically run vmstat with "vmstat sampling-period", e.g., "vmstat 5.
" The output looks like this: procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 20 0 195540 32772 6952 576752 0 0 11 12 38 43 1 0 99 0 22 2 195536 35988 6680 575132 6 0 2952 14 959 16375 72 21 4 3 The first line is your total system average since boot; typically this will not be very useful, since you are interested in what is causing problems NOW. Iostat To get more details of io, use iostat -x. What’s new in Cassandra 0.7: expiring columns. Sometimes, data comes with an expiration date, either by its nature or because it’s simply intractable to keep all of a rapidly growing dataset indefinitely. In most databases, the only way to deal with such expiring data is to write a job running periodically to delete what is expired. Unfortunately, this is usually both error-prone and inefficient: not only do you have to issue a high volume of deletions, but you often also have to scan through lots of data to find what is expired.
DataStax Cassandra 0.8 Documentation. DataStax Cassandra 0.7 Documentation. Tokens, Partitioners, and the Ring. Operations. Hardware See CassandraHardware Tuning See PerformanceTuning. Cassandra load balancing. Database design - What's The Best Practice In Designing A Cassandra Data Model. Cassandra: RandomPartitioner vs OrderPreservingPartitioner « Dominic Williams. When building a Cassandra cluster, the “key” question (sorry, that’s weak) is whether to use the RandomPartitioner (RP), or the OrderPreservingPartitioner (OPP).
These control how your data is distributed over your nodes. Once you have chosen your partitioner, you cannot change without wiping your data, so think carefully! For Cassandra newbies, like me and my team of HBasers wanting to try a quick port of our project (more on why in another post) nailing the exact issues is quite daunting. Driftx/chiton - GitHub. Apache Cassandra Glossary. API. User Guide - GitHub. Hector – a Java Cassandra client. Zznate/cassandra-tutorial - GitHub. Up and running with cassandra.